UniPT: Universal Parallel Tuning for Transfer Learning with Efficient Parameter and Memory
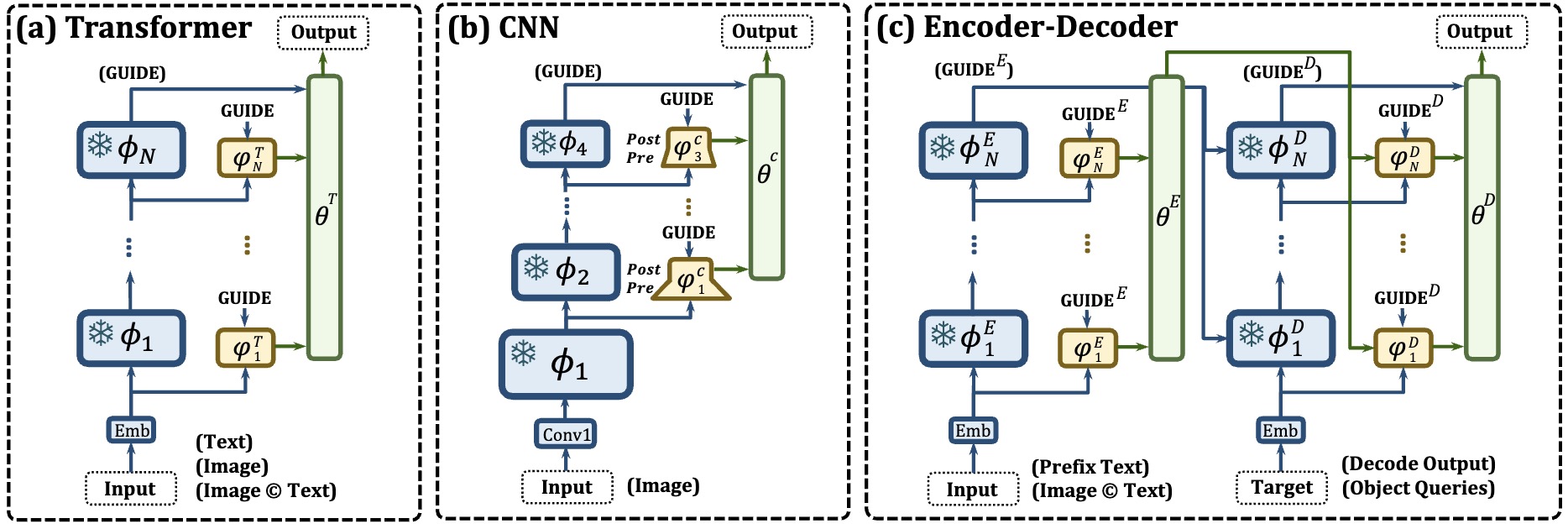
Parameter-efficient transfer learning (PETL), i.e., fine-tuning a small portion of parameters, is an effective strategy for adapting pre-trained models to downstream domains. To further reduce the memory demand, recent PETL works focus on the more valuable memory-efficient characteristic. In this paper, we argue that the scalability, adaptability, and generalizability of state-of-the-art methods are hindered by structural dependency and pertinency on specific pre-trained backbones. To this end, we propose a new memory-efficient PETL strategy, Universal Parallel Tuning (UniPT), to mitigate these weaknesses. Specifically, we facilitate the transfer process via a lightweight and learnable parallel network, which consists of: 1) A parallel interaction module that decouples the sequential connections and processes the intermediate activations detachedly from the pre-trained network. 2) A confidence aggregation module that learns optimal strategies adaptively for integrating cross-layer features. We evaluate UniPT with different backbones (e.g., T5, VSE$\infty$, CLIP4Clip, Clip-ViL, and MDETR) on various vision-and-language and pure NLP tasks. Extensive ablations on 18 datasets have validated that UniPT can not only dramatically reduce memory consumption and outperform the best competitor, but also achieve competitive performance over other plain PETL methods with lower training memory overhead. Our code is publicly available at: https://github.com/Paranioar/UniPT.
PDF Abstract




 MS COCO
MS COCO
 GLUE
GLUE
 MultiNLI
MultiNLI
 QNLI
QNLI
 Flickr30k
Flickr30k
 MRPC
MRPC
 CoLA
CoLA
 MSR-VTT
MSR-VTT
 GQA
GQA
 Visual Question Answering v2.0
Visual Question Answering v2.0
 RefCOCO
RefCOCO
 MSVD
MSVD
