RoboFusion: Towards Robust Multi-Modal 3D Object Detection via SAM
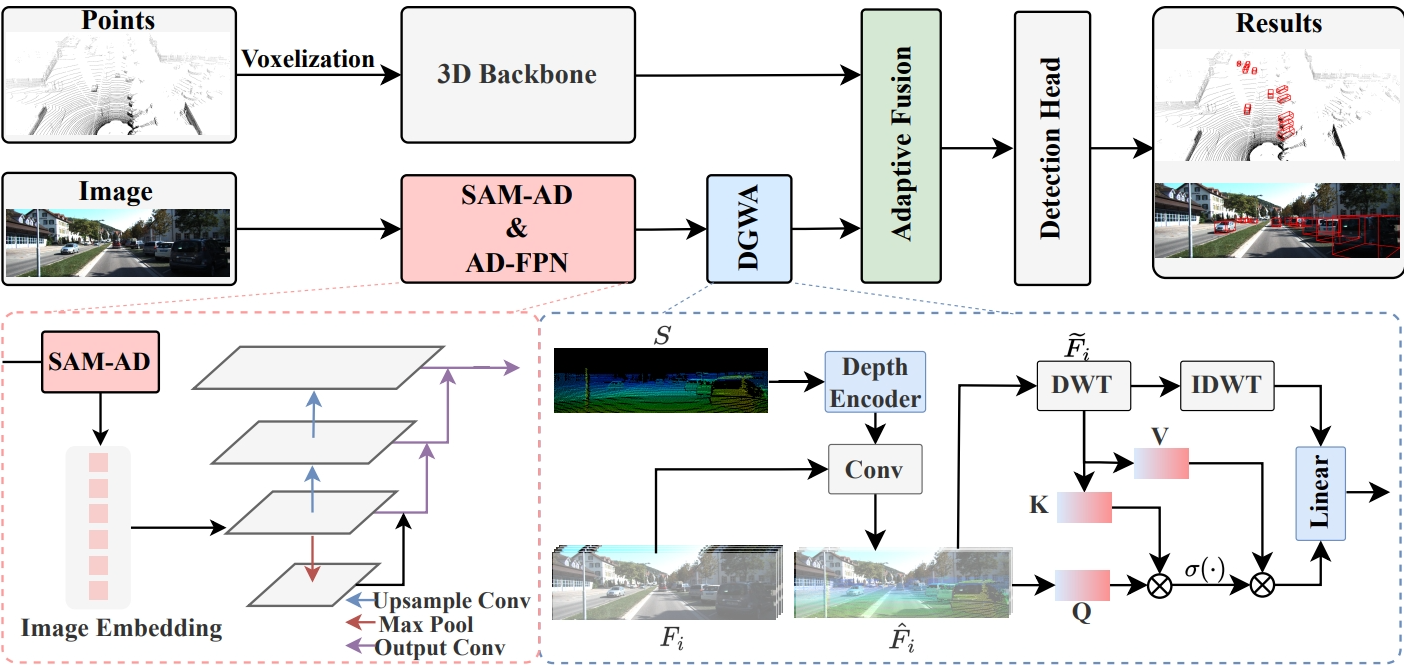
Multi-modal 3D object detectors are dedicated to exploring secure and reliable perception systems for autonomous driving (AD).Although achieving state-of-the-art (SOTA) performance on clean benchmark datasets, they tend to overlook the complexity and harsh conditions of real-world environments. With the emergence of visual foundation models (VFMs), opportunities and challenges are presented for improving the robustness and generalization of multi-modal 3D object detection in AD. Therefore, we propose RoboFusion, a robust framework that leverages VFMs like SAM to tackle out-of-distribution (OOD) noise scenarios. We first adapt the original SAM for AD scenarios named SAM-AD. To align SAM or SAM-AD with multi-modal methods, we then introduce AD-FPN for upsampling the image features extracted by SAM. We employ wavelet decomposition to denoise the depth-guided images for further noise reduction and weather interference. At last, we employ self-attention mechanisms to adaptively reweight the fused features, enhancing informative features while suppressing excess noise. In summary, RoboFusion significantly reduces noise by leveraging the generalization and robustness of VFMs, thereby enhancing the resilience of multi-modal 3D object detection. Consequently, RoboFusion achieves SOTA performance in noisy scenarios, as demonstrated by the KITTI-C and nuScenes-C benchmarks. Code is available at https://github.com/adept-thu/RoboFusion.
PDF Abstract




 KITTI
KITTI
 nuScenes
nuScenes
