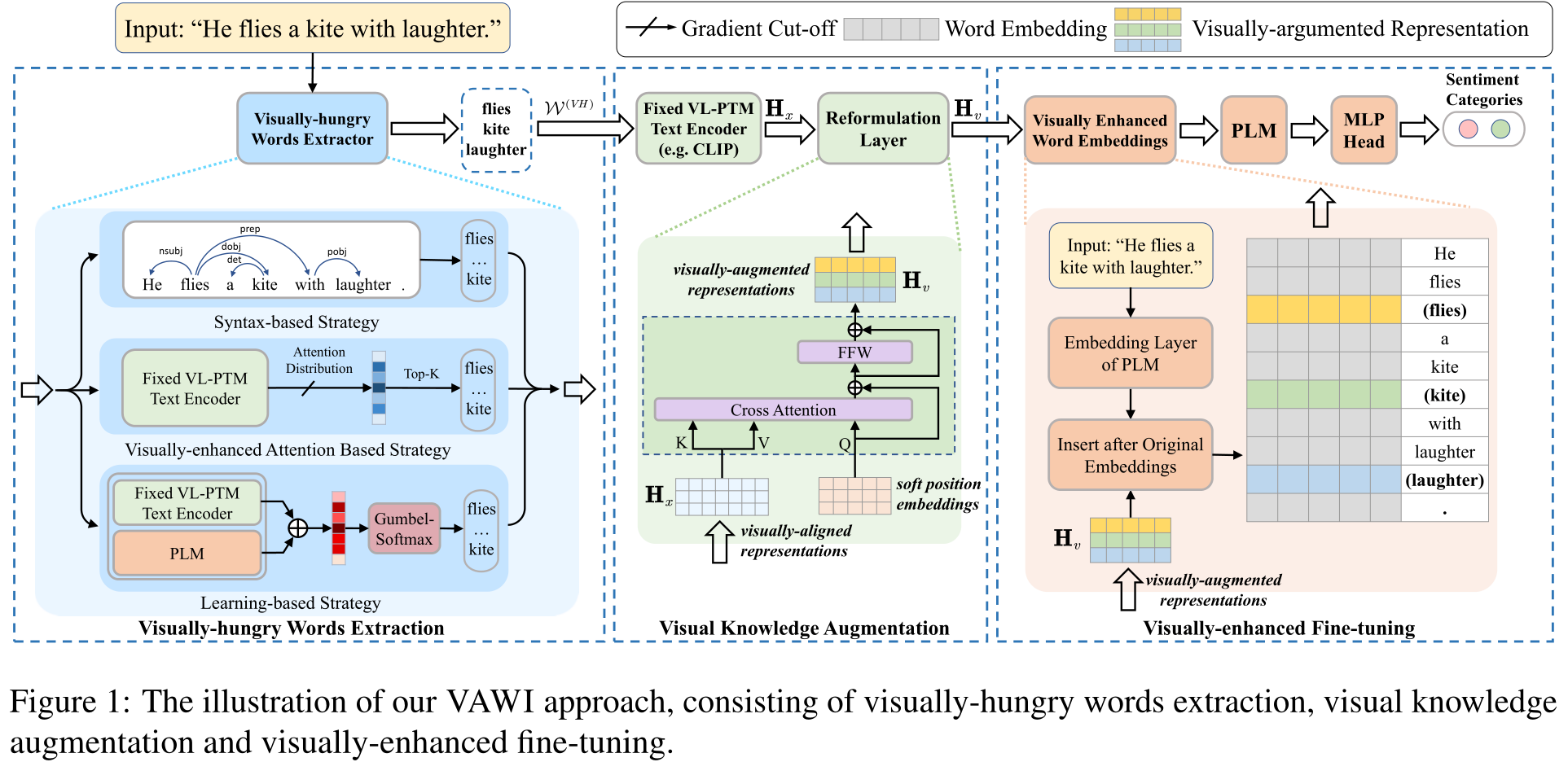
Visually-augmented pretrained language models for NLP tasks without images
Although pre-trained language models~(PLMs) have shown impressive performance by text-only self-supervised training, they are found lack of visual semantics or commonsense. Existing solutions often rely on explicit images for visual knowledge augmentation (requiring time-consuming retrieval or generation), and they also conduct the augmentation for the whole input text, without considering whether it is actually needed in specific inputs or tasks. To address these issues, we propose a novel \textbf{V}isually-\textbf{A}ugmented fine-tuning approach that can be generally applied to various PLMs or NLP tasks, \textbf{W}ithout using any retrieved or generated \textbf{I}mages, namely \textbf{VAWI}. Experimental results show that our approach can consistently improve the performance of BERT, RoBERTa, BART, and T5 at different scales, and outperform several competitive baselines on ten tasks. Our codes and data are publicly available at~\url{https://github.com/RUCAIBox/VAWI}.
PDF Abstract
 GLUE
GLUE
 QNLI
QNLI
 CommonsenseQA
CommonsenseQA
