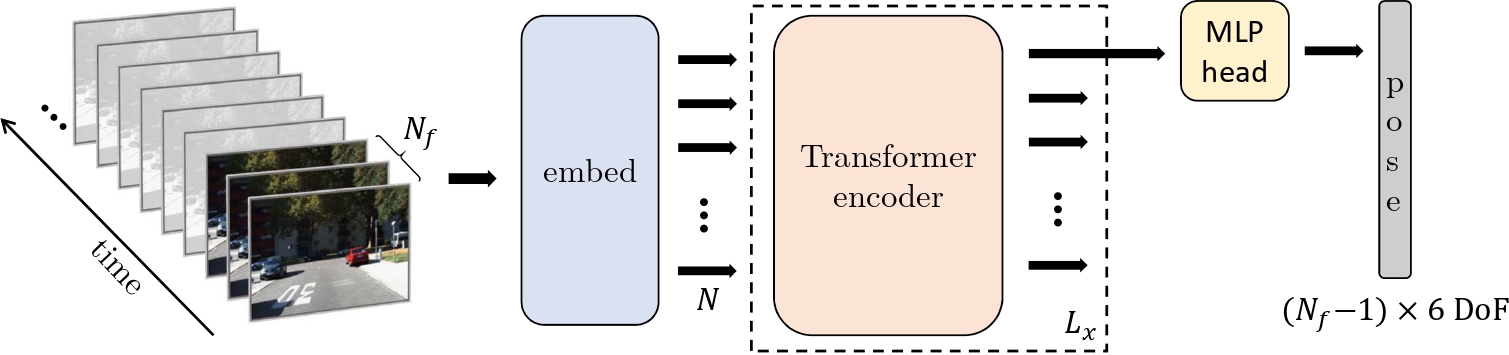
Transformer-based model for monocular visual odometry: a video understanding approach
Estimating the camera's pose given images of a single camera is a traditional task in mobile robots and autonomous vehicles. This problem is called monocular visual odometry and it often relies on geometric approaches that require considerable engineering effort for a specific scenario. Deep learning methods have shown to be generalizable after proper training and a large amount of available data. Transformer-based architectures have dominated the state-of-the-art in natural language processing and computer vision tasks, such as image and video understanding. In this work, we deal with the monocular visual odometry as a video understanding task to estimate the 6-DoF camera's pose. We contribute by presenting the TSformer-VO model based on spatio-temporal self-attention mechanisms to extract features from clips and estimate the motions in an end-to-end manner. Our approach achieved competitive state-of-the-art performance compared with geometry-based and deep learning-based methods on the KITTI visual odometry dataset, outperforming the DeepVO implementation highly accepted in the visual odometry community.
PDF Abstract


 KITTI
KITTI
