ODM3D: Alleviating Foreground Sparsity for Semi-Supervised Monocular 3D Object Detection
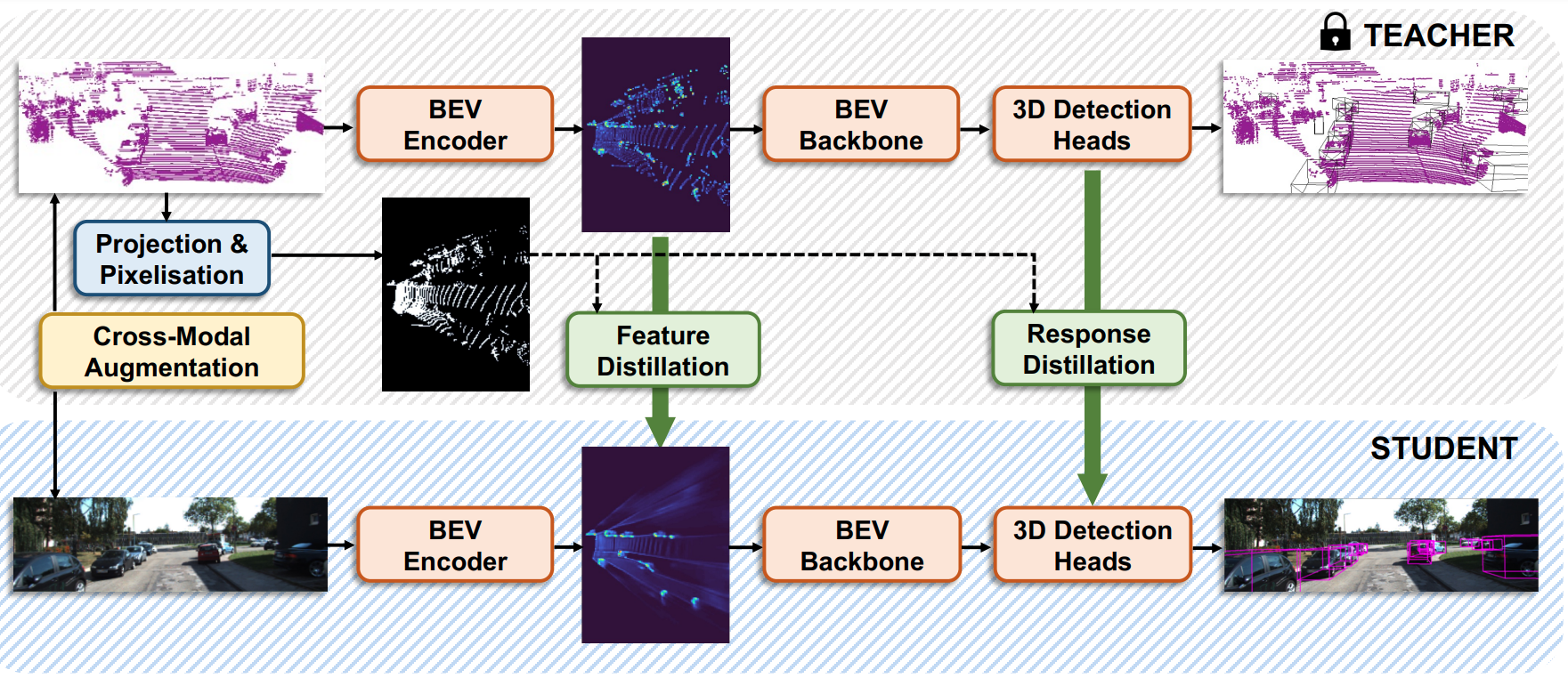
Monocular 3D object detection (M3OD) is a significant yet inherently challenging task in autonomous driving due to absence of explicit depth cues in a single RGB image. In this paper, we strive to boost currently underperforming monocular 3D object detectors by leveraging an abundance of unlabelled data via semi-supervised learning. Our proposed ODM3D framework entails cross-modal knowledge distillation at various levels to inject LiDAR-domain knowledge into a monocular detector during training. By identifying foreground sparsity as the main culprit behind existing methods' suboptimal training, we exploit the precise localisation information embedded in LiDAR points to enable more foreground-attentive and efficient distillation via the proposed BEV occupancy guidance mask, leading to notably improved knowledge transfer and M3OD performance. Besides, motivated by insights into why existing cross-modal GT-sampling techniques fail on our task at hand, we further design a novel cross-modal object-wise data augmentation strategy for effective RGB-LiDAR joint learning. Our method ranks 1st in both KITTI validation and test benchmarks, significantly surpassing all existing monocular methods, supervised or semi-supervised, on both BEV and 3D detection metrics.
PDF Abstract






 KITTI
KITTI
