MM-Interleaved: Interleaved Image-Text Generative Modeling via Multi-modal Feature Synchronizer
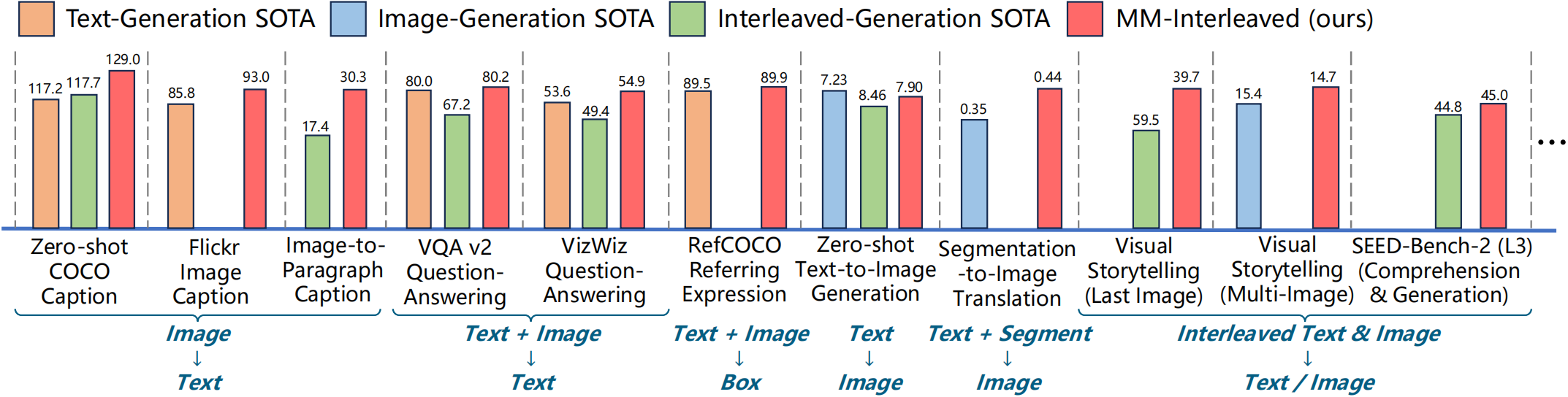
Developing generative models for interleaved image-text data has both research and practical value. It requires models to understand the interleaved sequences and subsequently generate images and text. However, existing attempts are limited by the issue that the fixed number of visual tokens cannot efficiently capture image details, which is particularly problematic in the multi-image scenarios. To address this, this paper presents MM-Interleaved, an end-to-end generative model for interleaved image-text data. It introduces a multi-scale and multi-image feature synchronizer module, allowing direct access to fine-grained image features in the previous context during the generation process. MM-Interleaved is end-to-end pre-trained on both paired and interleaved image-text corpora. It is further enhanced through a supervised fine-tuning phase, wherein the model improves its ability to follow complex multi-modal instructions. Experiments demonstrate the versatility of MM-Interleaved in recognizing visual details following multi-modal instructions and generating consistent images following both textual and visual conditions. Code and models are available at \url{https://github.com/OpenGVLab/MM-Interleaved}.
PDF Abstract
 MS COCO
MS COCO
 Visual Question Answering
Visual Question Answering
 ADE20K
ADE20K
 GQA
GQA
 RefCOCO
RefCOCO
 OK-VQA
OK-VQA
 TextVQA
TextVQA
 VisDial
VisDial
 NoCaps
NoCaps
 VizWiz
VizWiz
 VIST
VIST
 MMC4
MMC4
