Kinematic 3D Object Detection in Monocular Video
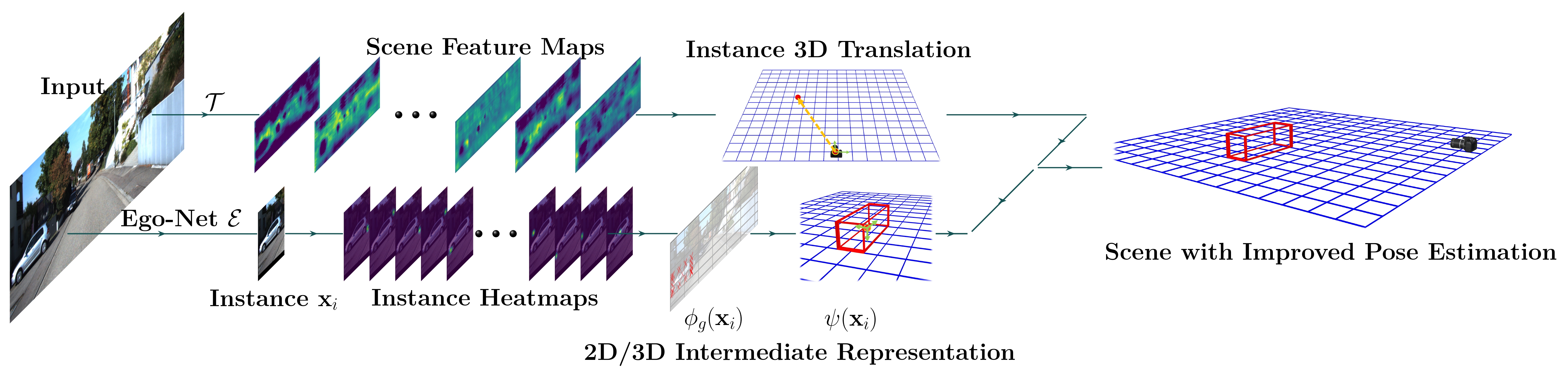
Perceiving the physical world in 3D is fundamental for self-driving applications. Although temporal motion is an invaluable resource to human vision for detection, tracking, and depth perception, such features have not been thoroughly utilized in modern 3D object detectors. In this work, we propose a novel method for monocular video-based 3D object detection which carefully leverages kinematic motion to improve precision of 3D localization. Specifically, we first propose a novel decomposition of object orientation as well as a self-balancing 3D confidence. We show that both components are critical to enable our kinematic model to work effectively. Collectively, using only a single model, we efficiently leverage 3D kinematics from monocular videos to improve the overall localization precision in 3D object detection while also producing useful by-products of scene dynamics (ego-motion and per-object velocity). We achieve state-of-the-art performance on monocular 3D object detection and the Bird's Eye View tasks within the KITTI self-driving dataset.
PDF Abstract ECCV 2020 PDF ECCV 2020 Abstract




 KITTI
KITTI

