DID-M3D: Decoupling Instance Depth for Monocular 3D Object Detection
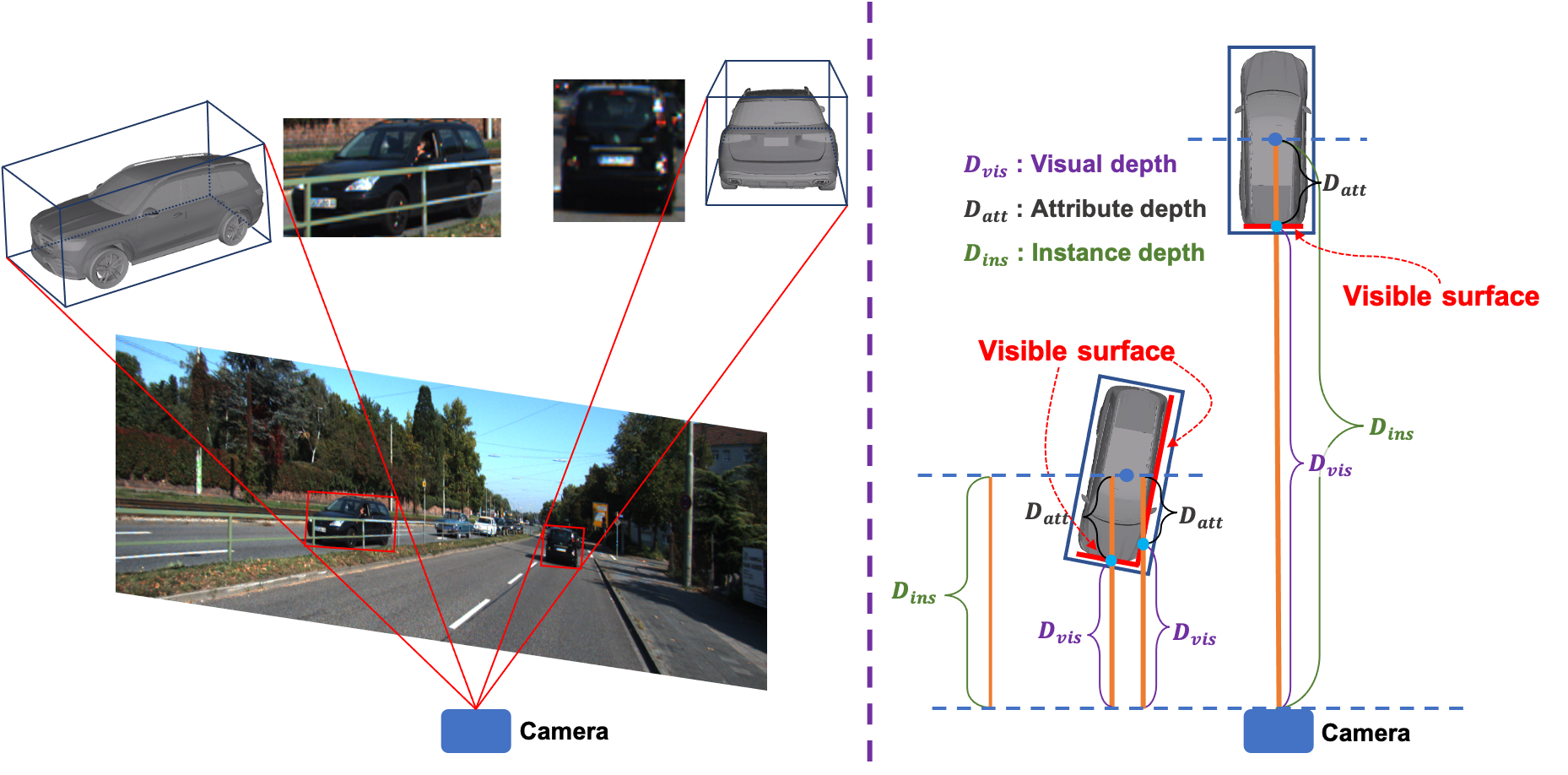
Monocular 3D detection has drawn much attention from the community due to its low cost and setup simplicity. It takes an RGB image as input and predicts 3D boxes in the 3D space. The most challenging sub-task lies in the instance depth estimation. Previous works usually use a direct estimation method. However, in this paper we point out that the instance depth on the RGB image is non-intuitive. It is coupled by visual depth clues and instance attribute clues, making it hard to be directly learned in the network. Therefore, we propose to reformulate the instance depth to the combination of the instance visual surface depth (visual depth) and the instance attribute depth (attribute depth). The visual depth is related to objects' appearances and positions on the image. By contrast, the attribute depth relies on objects' inherent attributes, which are invariant to the object affine transformation on the image. Correspondingly, we decouple the 3D location uncertainty into visual depth uncertainty and attribute depth uncertainty. By combining different types of depths and associated uncertainties, we can obtain the final instance depth. Furthermore, data augmentation in monocular 3D detection is usually limited due to the physical nature, hindering the boost of performance. Based on the proposed instance depth disentanglement strategy, we can alleviate this problem. Evaluated on KITTI, our method achieves new state-of-the-art results, and extensive ablation studies validate the effectiveness of each component in our method. The codes are released at https://github.com/SPengLiang/DID-M3D.
PDF Abstract





 KITTI
KITTI
