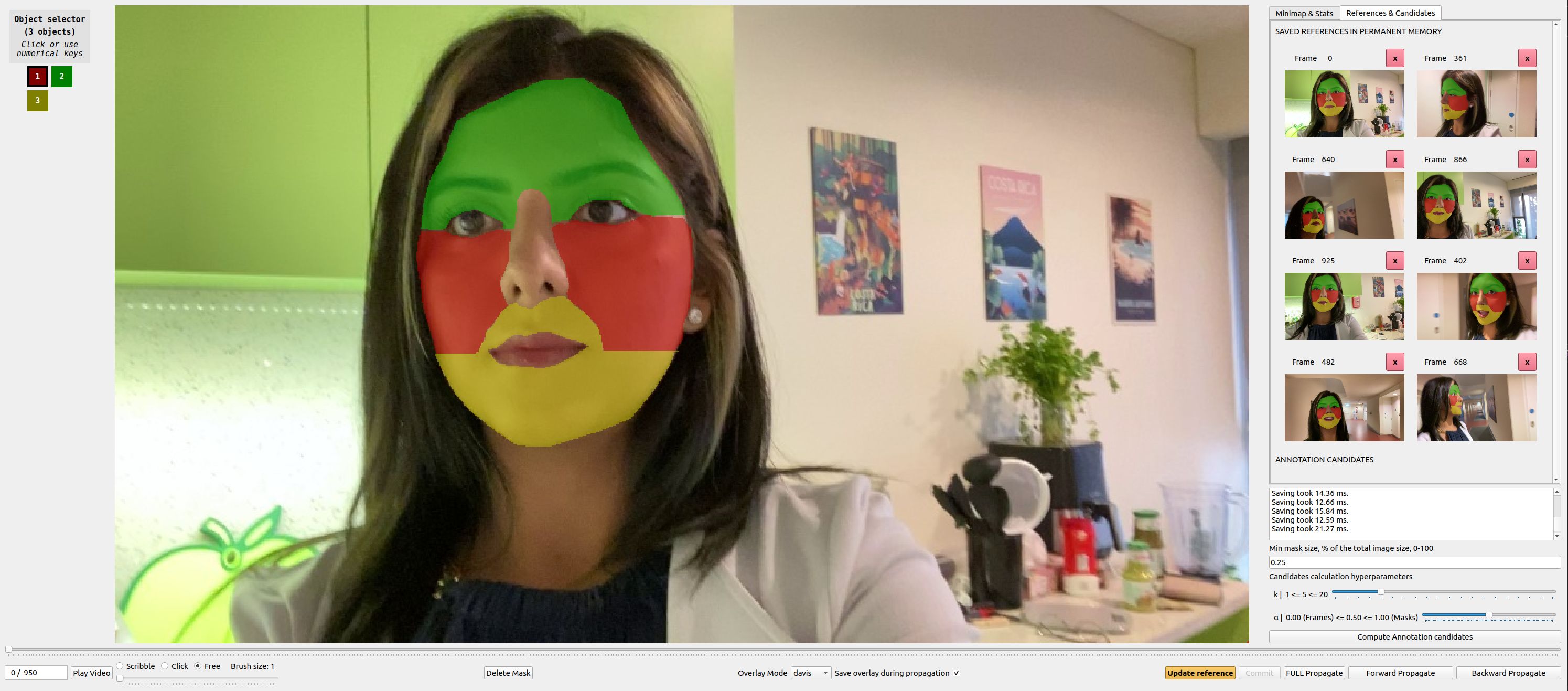
XMem++: Production-level Video Segmentation From Few Annotated Frames
Despite advancements in user-guided video segmentation, extracting complex objects consistently for highly complex scenes is still a labor-intensive task, especially for production. It is not uncommon that a majority of frames need to be annotated. We introduce a novel semi-supervised video object segmentation (SSVOS) model, XMem++, that improves existing memory-based models, with a permanent memory module. Most existing methods focus on single frame annotations, while our approach can effectively handle multiple user-selected frames with varying appearances of the same object or region. Our method can extract highly consistent results while keeping the required number of frame annotations low. We further introduce an iterative and attention-based frame suggestion mechanism, which computes the next best frame for annotation. Our method is real-time and does not require retraining after each user input. We also introduce a new dataset, PUMaVOS, which covers new challenging use cases not found in previous benchmarks. We demonstrate SOTA performance on challenging (partial and multi-class) segmentation scenarios as well as long videos, while ensuring significantly fewer frame annotations than any existing method. Project page: https://max810.github.io/xmem2-project-page/
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract




 DAVIS
DAVIS
 YouTube-VOS 2018
YouTube-VOS 2018
 MOSE
MOSE
 LVOS
LVOS
