Search Results for author:
Found 329 papers, 134 papers with code
PRISM: A Promptable and Robust Interactive Segmentation Model with Visual Prompts
(3) Corrective learning.
FiLo: Zero-Shot Anomaly Detection by Fine-Grained Description and High-Quality Localization
Zero-shot anomaly detection (ZSAD) methods entail detecting anomalies directly without access to any known normal or abnormal samples within the target item categories.
Arena: A Patch-of-Interest ViT Inference Acceleration System for Edge-Assisted Video Analytics
In this paper, we find visual foundation models like Vision Transformer (ViT) also have a dedicated acceleration mechanism for video analytics.
Fuxi-DA: A Generalized Deep Learning Data Assimilation Framework for Assimilating Satellite Observations
Data assimilation (DA), as an indispensable component within contemporary Numerical Weather Prediction (NWP) systems, plays a crucial role in generating the analysis that significantly impacts forecast performance.
360°REA: Towards A Reusable Experience Accumulation with 360° Assessment for Multi-Agent System
The framework employs a novel 360{\deg} performance assessment method for multi-perspective performance evaluation with fine-grained assessment.

Multi-level Graph Subspace Contrastive Learning for Hyperspectral Image Clustering
Multi-level graph subspace contrastive learning: multi-level contrastive learning was conducted to obtain local-global joint graph representations, to improve the consistency of the positive samples between views, and to obtain more robust graph embeddings.


Collaborative Feedback Discriminative Propagation for Video Super-Resolution
However, inaccurate alignment usually leads to aligned features with significant artifacts, which will be accumulated during propagation and thus affect video restoration.

On the Scalability of Diffusion-based Text-to-Image Generation
On the data scaling side, we show the quality and diversity of the training set matters more than simply dataset size.


NeRFCodec: Neural Feature Compression Meets Neural Radiance Fields for Memory-Efficient Scene Representation
The emergence of Neural Radiance Fields (NeRF) has greatly impacted 3D scene modeling and novel-view synthesis.

The state-of-the-art in Cardiac MRI Reconstruction: Results of the CMRxRecon Challenge in MICCAI 2023
To address this issue, we organized the Cardiac MRI Reconstruction Challenge (CMRxRecon) in 2023, in collaboration with the 26th International Conference on MICCAI.

From Two-Stream to One-Stream: Efficient RGB-T Tracking via Mutual Prompt Learning and Knowledge Distillation
Due to the complementary nature of visible light and thermal infrared modalities, object tracking based on the fusion of visible light images and thermal images (referred to as RGB-T tracking) has received increasing attention from researchers in recent years.

TDT-KWS: Fast And Accurate Keyword Spotting Using Token-and-duration Transducer
Designing an efficient keyword spotting (KWS) system that delivers exceptional performance on resource-constrained edge devices has long been a subject of significant attention.

GGRt: Towards Pose-free Generalizable 3D Gaussian Splatting in Real-time
Specifically, we design a novel joint learning framework that consists of an Iterative Pose Optimization Network (IPO-Net) and a Generalizable 3D-Gaussians (G-3DG) model.
LAN: Learning Adaptive Neighbors for Real-Time Insider Threat Detection
Moreover, LAN can be also applied to post-hoc ITD, surpassing 8 competitive baselines by at least 7. 70% and 4. 03% in AUC on two datasets.

LTGC: Long-tail Recognition via Leveraging LLMs-driven Generated Content
Long-tail recognition is challenging because it requires the model to learn good representations from tail categories and address imbalances across all categories.
Towards Effective Usage of Human-Centric Priors in Diffusion Models for Text-based Human Image Generation
Vanilla text-to-image diffusion models struggle with generating accurate human images, commonly resulting in imperfect anatomies such as unnatural postures or disproportionate limbs. Existing methods address this issue mostly by fine-tuning the model with extra images or adding additional controls -- human-centric priors such as pose or depth maps -- during the image generation phase.

Generalizable Whole Slide Image Classification with Fine-Grained Visual-Semantic Interaction
It is designed to enhance the model's generalizability by leveraging the interaction between localized visual patterns and fine-grained pathological semantics.

Improving LLM-based Machine Translation with Systematic Self-Correction
Large Language Models (LLMs) have achieved impressive results in Machine Translation (MT).

From Noise to Clarity: Unraveling the Adversarial Suffix of Large Language Model Attacks via Translation of Text Embeddings
The safety defense methods of Large language models(LLMs) stays limited because the dangerous prompts are manually curated to just few known attack types, which fails to keep pace with emerging varieties.
Gradual Residuals Alignment: A Dual-Stream Framework for GAN Inversion and Image Attribute Editing
GAN-based image attribute editing firstly leverages GAN Inversion to project real images into the latent space of GAN and then manipulates corresponding latent codes.
CIF-Bench: A Chinese Instruction-Following Benchmark for Evaluating the Generalizability of Large Language Models
The advancement of large language models (LLMs) has enhanced the ability to generalize across a wide range of unseen natural language processing (NLP) tasks through instruction-following.
Phrase Grounding-based Style Transfer for Single-Domain Generalized Object Detection
Single-domain generalized object detection aims to enhance a model's generalizability to multiple unseen target domains using only data from a single source domain during training.

MOSformer: Momentum encoder-based inter-slice fusion transformer for medical image segmentation
2. 5D-based segmentation models bridge computational efficiency of 2D-based models and spatial perception capabilities of 3D-based models.
Instance Brownian Bridge as Texts for Open-vocabulary Video Instance Segmentation
To mold instance queries to follow Brownian bridge and accomplish alignment with class texts, we design Bridge-Text Alignment (BTA) to learn discriminative bridge-level representations of instances via contrastive objectives.


Keeping Deep Learning Models in Check: A History-Based Approach to Mitigate Overfitting
This classifier is then used to detect if a trained model is overfit.
Hierarchical Fashion Design with Multi-stage Diffusion Models
Cross-modal fashion synthesis and editing offer intelligent support to fashion designers by enabling the automatic generation and local modification of design drafts. While current diffusion models demonstrate commendable stability and controllability in image synthesis, they still face significant challenges in generating fashion design from abstract design elements and fine-grained editing. Abstract sensory expressions, \eg office, business, and party, form the high-level design concepts, while measurable aspects like sleeve length, collar type, and pant length are considered the low-level attributes of clothing. Controlling and editing fashion images using lengthy text descriptions poses a difficulty. In this paper, we propose HieraFashDiff, a novel fashion design method using the shared multi-stage diffusion model encompassing high-level design concepts and low-level clothing attributes in a hierarchical structure. Specifically, we categorized the input text into different levels and fed them in different time step to the diffusion model according to the criteria of professional clothing designers. HieraFashDiff allows designers to add low-level attributes after high-level prompts for interactive editing incrementally. In addition, we design a differentiable loss function in the sampling process with a mask to keep non-edit areas. Comprehensive experiments performed on our newly conducted Hierarchical fashion dataset, demonstrate that our proposed method outperforms other state-of-the-art competitors.
Contrastive Learning With Audio Discrimination For Customizable Keyword Spotting In Continuous Speech
Furthermore, experiments on the continuous speech dataset LibriSpeech demonstrate that, by incorporating audio discrimination, CLAD achieves significant performance gain over CL without audio discrimination.
Risk-anticipatory autonomous driving strategies considering vehicles' weights, based on hierarchical deep reinforcement learning
Autonomous vehicles (AVs) have the potential to prevent accidents caused by drivers' error and reduce road traffic risks.

Coordinated Planning of Offshore Charging Stations and Electrified Ships: A Case Study on Shanghai-Busan Maritime Route
Despite the success of electric vehicles on land, electrification of maritime ships is challenged by the dilemma of range anxiety and cargo-carrying capacity.
Token-Level Contrastive Learning with Modality-Aware Prompting for Multimodal Intent Recognition
To establish an optimal multimodal semantic environment for text modality, we develop a modality-aware prompting module (MAP), which effectively aligns and fuses features from text, video and audio modalities with similarity-based modality alignment and cross-modality attention mechanism.
 Ranked #2 on
Multimodal Intent Recognition
on MIntRec
Ranked #2 on
Multimodal Intent Recognition
on MIntRec

FuXi-S2S: An accurate machine learning model for global subseasonal forecasts
Skillful subseasonal forecasts beyond 2 weeks are crucial for a wide range of applications across various sectors of society.
Auto MC-Reward: Automated Dense Reward Design with Large Language Models for Minecraft
Many reinforcement learning environments (e. g., Minecraft) provide only sparse rewards that indicate task completion or failure with binary values.
Diffusion-based Blind Text Image Super-Resolution
Since text prior is important to guarantee the correctness of the restored text structure according to existing arts, we also propose a Text Diffusion Model (TDM) for text recognition which can guide IDM to generate text images with correct structures.

Negative Pre-aware for Noisy Cross-modal Matching
Since clean samples are easier distinguished by GMM with increasing noise, the memory bank can still maintain high quality at a high noise ratio.
The performance of multiple language models in identifying offensive language on social media
Text classification is an important topic in the field of natural language processing.

VOODOO 3D: Volumetric Portrait Disentanglement for One-Shot 3D Head Reenactment
We present a 3D-aware one-shot head reenactment method based on a fully volumetric neural disentanglement framework for source appearance and driver expressions.

MICRO: Model-Based Offline Reinforcement Learning with a Conservative Bellman Operator
This method trades off performance and robustness via introducing the robust Bellman operator into the algorithm.
FreestyleRet: Retrieving Images from Style-Diversified Queries
In this paper, we propose the Style-Diversified Query-Based Image Retrieval task, which enables retrieval based on various query styles.

Sketch Input Method Editor: A Comprehensive Dataset and Methodology for Systematic Input Recognition
With the recent surge in the use of touchscreen devices, free-hand sketching has emerged as a promising modality for human-computer interaction.

Novel OCT mosaicking pipeline with Feature- and Pixel-based registration
High-resolution Optical Coherence Tomography (OCT) images are crucial for ophthalmology studies but are limited by their relatively narrow field of view (FoV).
GP-NeRF: Generalized Perception NeRF for Context-Aware 3D Scene Understanding
Applying NeRF to downstream perception tasks for scene understanding and representation is becoming increasingly popular.
Taiyi: A Bilingual Fine-Tuned Large Language Model for Diverse Biomedical Tasks
The case study involving additional biomedical NLP tasks further shows Taiyi's considerable potential for bilingual biomedical multi-tasking.
Assessing Test-time Variability for Interactive 3D Medical Image Segmentation with Diverse Point Prompts
In this paper, we assess the test-time variability for interactive medical image segmentation with diverse point prompts.
SpectralGPT: Spectral Remote Sensing Foundation Model
The foundation model has recently garnered significant attention due to its potential to revolutionize the field of visual representation learning in a self-supervised manner.


InfMLLM: A Unified Framework for Visual-Language Tasks
Our experiments demonstrate that preserving the positional information of visual embeddings through the pool-adapter is particularly beneficial for tasks like visual grounding.
 Ranked #62 on
Visual Question Answering
on MM-Vet
Ranked #62 on
Visual Question Answering
on MM-Vet

Machine Learning Parameterization of the Multi-scale Kain-Fritsch (MSKF) Convection Scheme
The Weather Research and Forecast (WRF) model is used to generate training and testing data over South China at a horizontal resolution of 5 km.
Promise:Prompt-driven 3D Medical Image Segmentation Using Pretrained Image Foundation Models
To address prevalent issues in medical imaging, such as data acquisition challenges and label availability, transfer learning from natural to medical image domains serves as a viable strategy to produce reliable segmentation results.

CROP: Conservative Reward for Model-based Offline Policy Optimization
Offline reinforcement learning (RL) aims to optimize policy using collected data without online interactions.
FuXi-Extreme: Improving extreme rainfall and wind forecasts with diffusion model
State-of-the-art ML-based weather forecast models, such as FuXi, have demonstrated superior statistical forecast performance in comparison to the high-resolution forecasts (HRES) of the European Centre for Medium-Range Weather Forecasts (ECMWF).
Facial Data Minimization: Shallow Model as Your Privacy Filter
Face recognition service has been used in many fields and brings much convenience to people.

Unpaired MRI Super Resolution with Contrastive Learning
To this end, we propose an unpaired MRI SR approach that employs contrastive learning to enhance SR performance with limited HR training data.
On Generative Agents in Recommendation
Recommender systems are the cornerstone of today's information dissemination, yet a disconnect between offline metrics and online performance greatly hinders their development.

Prototype-based Aleatoric Uncertainty Quantification for Cross-modal Retrieval
In this paper, we propose a novel Prototype-based Aleatoric Uncertainty Quantification (PAU) framework to provide trustworthy predictions by quantifying the uncertainty arisen from the inherent data ambiguity.
 Ranked #16 on
Video Retrieval
on MSVD
Ranked #16 on
Video Retrieval
on MSVD
High-Fidelity Speech Synthesis with Minimal Supervision: All Using Diffusion Models
To address these issues, we propose a minimally-supervised high-fidelity speech synthesis method, where all modules are constructed based on the diffusion models.

NDC-Scene: Boost Monocular 3D Semantic Scene Completion in Normalized Device Coordinates Space
Monocular 3D Semantic Scene Completion (SSC) has garnered significant attention in recent years due to its potential to predict complex semantics and geometry shapes from a single image, requiring no 3D inputs.

 3D Semantic Scene Completion from a single 2D image
3D Semantic Scene Completion from a single 2D image
 3D Semantic Scene Completion from a single RGB image
3D Semantic Scene Completion from a single RGB image
Cross-City Matters: A Multimodal Remote Sensing Benchmark Dataset for Cross-City Semantic Segmentation using High-Resolution Domain Adaptation Networks
Artificial intelligence (AI) approaches nowadays have gained remarkable success in single-modality-dominated remote sensing (RS) applications, especially with an emphasis on individual urban environments (e. g., single cities or regions).
CMRxRecon: An open cardiac MRI dataset for the competition of accelerated image reconstruction
However, a limitation of CMR is its slow imaging speed, which causes patient discomfort and introduces artifacts in the images.
DOMAIN: MilDly COnservative Model-BAsed OfflINe Reinforcement Learning
However, uncertainty estimation is unreliable and leads to poor performance in certain scenarios, and the previous methods ignore differences between the model data, which brings great conservatism.
Implicit Neural Representation for MRI Parallel Imaging Reconstruction
Our approach represents reconstructed fully-sampled images as functions of voxel coordinates and prior feature vectors from undersampled images, addressing the generalization challenges of INR.
Research on Damage Analysis of Key Parts of UAV Flight Control System
A set of hardware in the loop simulation methods based on the UAV model is proposed to create fault data, which is used to judge the parts where faults happen.
Learning Speech Representation From Contrastive Token-Acoustic Pretraining
However, existing contrastive learning methods in the audio field focus on extracting global descriptive information for downstream audio classification tasks, making them unsuitable for TTS, VC, and ASR tasks.
Towards Privacy-Supporting Fall Detection via Deep Unsupervised RGB2Depth Adaptation
In this paper, we introduce a privacy-supporting solution that makes the RGB-trained model applicable in depth domain and utilizes depth data at test time for fall detection.
False Negative/Positive Control for SAM on Noisy Medical Images
The method couples multi-box prompt augmentation and an aleatoric uncertainty-based false-negative (FN) and false-positive (FP) correction (FNPC) strategy.
MonoNeRD: NeRF-like Representations for Monocular 3D Object Detection
To the best of our knowledge, this work is the first to introduce volume rendering for M3D, and demonstrates the potential of implicit reconstruction for image-based 3D perception.
IOB: Integrating Optimization Transfer and Behavior Transfer for Multi-Policy Reuse
Humans have the ability to reuse previously learned policies to solve new tasks quickly, and reinforcement learning (RL) agents can do the same by transferring knowledge from source policies to a related target task.

CATS v2: Hybrid encoders for robust medical segmentation
We fuse the information from the convolutional encoder and the transformer at the skip connections of different resolutions to form the final segmentation.
The All-Seeing Project: Towards Panoptic Visual Recognition and Understanding of the Open World
We present the All-Seeing (AS) project: a large-scale data and model for recognizing and understanding everything in the open world.

Reinforcement Learning-based Non-Autoregressive Solver for Traveling Salesman Problems
The Traveling Salesman Problem (TSP) is a well-known combinatorial optimization problem with broad real-world applications.
XMem++: Production-level Video Segmentation From Few Annotated Frames
Despite advancements in user-guided video segmentation, extracting complex objects consistently for highly complex scenes is still a labor-intensive task, especially for production.
Minimally-Supervised Speech Synthesis with Conditional Diffusion Model and Language Model: A Comparative Study of Semantic Coding
However, existing methods suffer from three problems: the high dimensionality and waveform distortion of discrete speech representations, the prosodic averaging problem caused by the duration prediction model in non-autoregressive frameworks, and the information redundancy and dimension explosion problems of existing semantic encoding methods.
COLosSAL: A Benchmark for Cold-start Active Learning for 3D Medical Image Segmentation
Cold-start AL is highly relevant in many practical scenarios but has been under-explored, especially for 3D medical segmentation tasks requiring substantial annotation effort.
PULSAR at MEDIQA-Sum 2023: Large Language Models Augmented by Synthetic Dialogue Convert Patient Dialogues to Medical Records
This paper describes PULSAR, our system submission at the ImageClef 2023 MediQA-Sum task on summarising patient-doctor dialogues into clinical records.

Semi-supervised Learning from Street-View Images and OpenStreetMap for Automatic Building Height Estimation
In this work, we propose a semi-supervised learning (SSL) method of automatically estimating building height from Mapillary SVI and OSM data to generate low-cost and open-source 3D city modeling in LoD1.
VesselMorph: Domain-Generalized Retinal Vessel Segmentation via Shape-Aware Representation
We map the intensity image and the tensor field to a latent space for feature extraction.

FuXi: A cascade machine learning forecasting system for 15-day global weather forecast
Over the past few years, due to the rapid development of machine learning (ML) models for weather forecasting, state-of-the-art ML models have shown superior performance compared to the European Centre for Medium-Range Weather Forecasts (ECMWF)'s high-resolution forecast (HRES) in 10-day forecasts at a spatial resolution of 0. 25 degree.
WiCo: Win-win Cooperation of Bottom-up and Top-down Referring Image Segmentation
Bottom-up methods are mainly perturbed by Inferior Positive (IP) errors due to the lack of prior object information.

ADDP: Learning General Representations for Image Recognition and Generation with Alternating Denoising Diffusion Process
In each denoising step, our method first decodes pixels from previous VQ tokens, then generates new VQ tokens from the decoded pixels.
M$^3$Fair: Mitigating Bias in Healthcare Data through Multi-Level and Multi-Sensitive-Attribute Reweighting Method
In healthcare AI, these attributes can play a significant role in determining the quality of care that individuals receive.
PULSAR: Pre-training with Extracted Healthcare Terms for Summarising Patients' Problems and Data Augmentation with Black-box Large Language Models
Medical progress notes play a crucial role in documenting a patient's hospital journey, including his or her condition, treatment plan, and any updates for healthcare providers.
Sonicverse: A Multisensory Simulation Platform for Embodied Household Agents that See and Hear
We introduce Sonicverse, a multisensory simulation platform with integrated audio-visual simulation for training household agents that can both see and hear.

The ObjectFolder Benchmark: Multisensory Learning with Neural and Real Objects
We introduce the ObjectFolder Benchmark, a benchmark suite of 10 tasks for multisensory object-centric learning, centered around object recognition, reconstruction, and manipulation with sight, sound, and touch.
Do You Hear The People Sing? Key Point Analysis via Iterative Clustering and Abstractive Summarisation
Furthermore, evaluating key points is crucial in ensuring that the automatically generated summaries are useful.
OVO: Open-Vocabulary Occupancy
Semantic occupancy prediction aims to infer dense geometry and semantics of surroundings for an autonomous agent to operate safely in the 3D environment.
Text-Video Retrieval with Disentangled Conceptualization and Set-to-Set Alignment
In this paper, we propose the Disentangled Conceptualization and Set-to-set Alignment (DiCoSA) to simulate the conceptualizing and reasoning process of human beings.
TG-VQA: Ternary Game of Video Question Answering
Video question answering aims at answering a question about the video content by reasoning the alignment semantics within them.
Correcting for Interference in Experiments: A Case Study at Douyin
We formalize the problem of inference in such experiments as one of policy evaluation.
COSST: Multi-organ Segmentation with Partially Labeled Datasets Using Comprehensive Supervisions and Self-training
We revisit the problem from a perspective of partial label supervision signals and identify two signals derived from ground truth and one from pseudo labels.

Benchmarking the Physical-world Adversarial Robustness of Vehicle Detection
Thus, virtual simulation experiments can provide a solution to this challenge.
CryoFormer: Continuous Heterogeneous Cryo-EM Reconstruction using Transformer-based Neural Representations
Cryo-electron microscopy (cryo-EM) allows for the high-resolution reconstruction of 3D structures of proteins and other biomolecules.
EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object Pose Estimation
In this paper, we propose the EPro-PnP, a probabilistic PnP layer for general end-to-end pose estimation, which outputs a distribution of pose with differentiable probability density on the SE(3) manifold.
 Ranked #4 on
6D Pose Estimation using RGB
on LineMOD
Ranked #4 on
6D Pose Estimation using RGB
on LineMOD


Learning A Sparse Transformer Network for Effective Image Deraining
To overcome this problem, we propose an effective DeRaining network, Sparse Transformer (DRSformer) that can adaptively keep the most useful self-attention values for feature aggregation so that the aggregated features better facilitate high-quality image reconstruction.
Video Action Recognition with Attentive Semantic Units
Supervised by the semantics of action labels, recent works adapt the visual branch of VLMs to learn video representations.


DiffusionRet: Generative Text-Video Retrieval with Diffusion Model
Existing text-video retrieval solutions are, in essence, discriminant models focused on maximizing the conditional likelihood, i. e., p(candidates|query).
Ranked #15 on
Video Retrieval
on MSVD
SSL^2: Self-Supervised Learning meets Semi-Supervised Learning: Multiple Sclerosis Segmentation in 7T-MRI from large-scale 3T-MRI
A potential solution is to leverage the information available in large public datasets in conjunction with a target dataset which only has limited labeled data.

TwERC: High Performance Ensembled Candidate Generation for Ads Recommendation at Twitter
We focus on the candidate generation phase of a large-scale ads recommendation problem in this paper, and present a machine learning first heterogeneous re-architecture of this stage which we term TwERC.

An Adaptive Plug-and-Play Network for Few-Shot Learning
Few-shot learning (FSL) requires a model to classify new samples after learning from only a few samples.
Boosting Low-Data Instance Segmentation by Unsupervised Pre-training with Saliency Prompt
Inspired by the recent success of the Prompting technique, we introduce a new pre-training method that boosts QEIS models by giving Saliency Prompt for queries/kernels.
UNAEN: Unsupervised Abnormality Extraction Network for MRI Motion Artifact Reduction
Our results substantiate the potential of UNAEN as a promising solution applicable in real-world clinical environments, with the capability to enhance diagnostic accuracy and facilitate image-guided therapies.
OccluMix: Towards De-Occlusion Virtual Try-on by Semantically-Guided Mixup
Image Virtual try-on aims at replacing the cloth on a personal image with a garment image (in-shop clothes), which has attracted increasing attention from the multimedia and computer vision communities.
Guided Recommendation for Model Fine-Tuning
With thousands of historical training jobs, a recommendation system can be learned to predict the model selection score given the features of the dataset and the model as input.

StyleGene: Crossover and Mutation of Region-Level Facial Genes for Kinship Face Synthesis
As cycle-like losses are designed to measure the L_2 distances between the output of Gene Decoder and image encoder, and that between the output of LGE and IGE, only face images are required to train our framework, i. e. no paired kinship face data is required.
Clusterformer: Cluster-based Transformer for 3D Object Detection in Point Clouds
Attributed to the unstructured and sparse nature of point clouds, the transformer shows greater potential in point clouds data processing.
Biomedical image analysis competitions: The state of current participation practice
Of these, 84% were based on standard architectures.
SteerNeRF: Accelerating NeRF Rendering via Smooth Viewpoint Trajectory
Neural Radiance Fields (NeRF) have demonstrated superior novel view synthesis performance but are slow at rendering.
See, Hear, and Feel: Smart Sensory Fusion for Robotic Manipulation
Humans use all of their senses to accomplish different tasks in everyday activities.
A Differentiable Semantic Metric Approximation in Probabilistic Embedding for Cross-Modal Retrieval
To verify the effectiveness of our approach, extensive experiments are conducted on MS-COCO, CUB Captions, and Flickr30K, which are commonly used in cross-modal retrieval.
Entropy-Driven Mixed-Precision Quantization for Deep Network Design
Deploying deep convolutional neural networks on Internet-of-Things (IoT) devices is challenging due to the limited computational resources, such as limited SRAM memory and Flash storage.

Uni-Perceiver v2: A Generalist Model for Large-Scale Vision and Vision-Language Tasks
In this paper, we propose Uni-Perceiver v2, which is the first generalist model capable of handling major large-scale vision and vision-language tasks with competitive performance.
Bayesian Layer Graph Convolutioanl Network for Hyperspetral Image Classification
In recent years, research on hyperspectral image (HSI) classification has continuous progress on introducing deep network models, and recently the graph convolutional network (GCN) based models have shown impressive performance.

Detecting Line Segments in Motion-blurred Images with Events
To robustly detect line segments over motion blurs, we propose to leverage the complementary information of images and events.

VTC-LFC: Vision Transformer Compression with Low-Frequency Components
Although Vision transformers (ViTs) have recently dominated many vision tasks, deploying ViT models on resource-limited devices remains a challenging problem.
Towards Consistency and Complementarity: A Multiview Graph Information Bottleneck Approach
In this paper, we propose a novel Multiview Variational Graph Information Bottleneck (MVGIB) principle to maximize the agreement for common representations and the disagreement for view-specific representations.
Toward 3D Spatial Reasoning for Human-like Text-based Visual Question Answering
Under this setting, these 2D spatial reasoning approaches cannot distinguish the fine-grain spatial relations between visual objects and scene texts on the same image plane, thereby impairing the interpretability and performance of TextVQA models.

MimCo: Masked Image Modeling Pre-training with Contrastive Teacher
Specifically, MimCo takes a pre-trained contrastive learning model as the teacher model and is pre-trained with two types of learning targets: patch-level and image-level reconstruction losses.
Cats: Complementary CNN and Transformer Encoders for Segmentation
We fuse the information from the convolutional encoder and the transformer, and pass it to the decoder to obtain the results.

Region-Based Evidential Deep Learning to Quantify Uncertainty and Improve Robustness of Brain Tumor Segmentation
Despite recent advances in the accuracy of brain tumor segmentation, the results still suffer from low reliability and robustness.

SBPF: Sensitiveness Based Pruning Framework For Convolutional Neural Network On Image Classification
Therefore, we propose a sensitiveness based method to evaluate the importance of each layer from the perspective of inference accuracy by adding extra damage for the original model.
Semantic Data Augmentation based Distance Metric Learning for Domain Generalization
Further, we provide an in-depth analysis of the mechanism and rational behind our approach, which gives us a better understanding of why leverage logits in lieu of features can help domain generalization.
DnSwin: Toward Real-World Denoising via Continuous Wavelet Sliding-Transformer
Real-world image denoising is a practical image restoration problem that aims to obtain clean images from in-the-wild noisy inputs.

Criteria Comparative Learning for Real-scene Image Super-Resolution
Inspired by the observation that the contrastive relationship could also exist between the criteria, in this work, we propose a novel training paradigm for RealSR, named Criteria Comparative Learning (Cria-CL), by developing contrastive losses defined on criteria instead of image patches.
Large-Kernel Attention for 3D Medical Image Segmentation
The performance improvement due to the proposed LK attention module was also statistically validated.
Cross Vision-RF Gait Re-identification with Low-cost RGB-D Cameras and mmWave Radars
Human identification is a key requirement for many applications in everyday life, such as personalized services, automatic surveillance, continuous authentication, and contact tracing during pandemics, etc.


Dynamic Gradient Reactivation for Backward Compatible Person Re-identification
To address this issue, we propose the Ranking-based Backward Compatible Learning (RBCL), which directly optimizes the ranking metric between new features and old features.
Human Treelike Tubular Structure Segmentation: A Comprehensive Review and Future Perspectives
Various structures in human physiology follow a treelike morphology, which often expresses complexity at very fine scales.
DLME: Deep Local-flatness Manifold Embedding
To overcome the underconstrained embedding problem, we design a loss and theoretically demonstrate that it leads to a more suitable embedding based on the local flatness.
 Ranked #2 on
Image Classification
on ImageNet-100
Ranked #2 on
Image Classification
on ImageNet-100
Location reference recognition from texts: A survey and comparison
Further, there lacks a comprehensive review and comparison of existing approaches for location reference recognition, which is the first and a core step of geoparsing.
CGAR: Critic Guided Action Redistribution in Reinforcement Leaning
As discussed in this paper, under the settings of the off-policy actor critic algorithms, we demonstrate that the critic can bring more expected discounted rewards than or at least equal to the actor.
Real-World Image Super-Resolution by Exclusionary Dual-Learning
Real-world image super-resolution is a practical image restoration problem that aims to obtain high-quality images from in-the-wild input, has recently received considerable attention with regard to its tremendous application potentials.
Point-Teaching: Weakly Semi-Supervised Object Detection with Point Annotations
Point annotations are considerably more time-efficient than bounding box annotations.
Point RCNN: An Angle-Free Framework for Rotated Object Detection
To tackle this problem, we propose a purely angle-free framework for rotated object detection, called Point RCNN, which mainly consists of PointRPN and PointReg.
SwinVRNN: A Data-Driven Ensemble Forecasting Model via Learned Distribution Perturbation
We also compare four categories of perturbation methods for ensemble forecasting, i. e. fixed distribution perturbation, learned distribution perturbation, MC dropout, and multi model ensemble.
An Empirical Study on Distribution Shift Robustness From the Perspective of Pre-Training and Data Augmentation
With our empirical result obtained from 1, 330 models, we provide the following main observations: 1) ERM combined with data augmentation can achieve state-of-the-art performance if we choose a proper pre-trained model respecting the data property; 2) specialized algorithms further improve the robustness on top of ERM when handling a specific type of distribution shift, e. g., GroupDRO for spurious correlation and CORAL for large-scale out-of-distribution data; 3) Comparing different pre-training modes, architectures and data sizes, we provide novel observations about pre-training on distribution shift, which sheds light on designing or selecting pre-training strategy for different kinds of distribution shifts.
Unsupervised Representation Learning for 3D MRI Super Resolution with Degradation Adaptation
However, the difference in degradation representations between synthetic and authentic LR images suppresses the quality of SR images reconstructed from authentic LR images.

NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29. 00dB on DIV2K validation set.
Joint learning of object graph and relation graph for visual question answering
Modeling visual question answering(VQA) through scene graphs can significantly improve the reasoning accuracy and interpretability.
Multi-view Point Cloud Registration based on Evolutionary Multitasking with Bi-Channel Knowledge Sharing Mechanism
The modeling of multi-view point cloud registration as multi-task optimization are twofold.
Learning to Listen: Modeling Non-Deterministic Dyadic Facial Motion
We present a framework for modeling interactional communication in dyadic conversations: given multimodal inputs of a speaker, we autoregressively output multiple possibilities of corresponding listener motion.
Task Adaptive Parameter Sharing for Multi-Task Learning
TAPS solves a joint optimization problem which determines which layers to share with the base model and the value of the task-specific weights.
EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object Pose Estimation
The 2D-3D coordinates and corresponding weights are treated as intermediate variables learned by minimizing the KL divergence between the predicted and target pose distribution.
Ranked #6 on
6D Pose Estimation using RGB
on LineMOD
PMAL: Open Set Recognition via Robust Prototype Mining
Accordingly, the embedding space can be better optimized to discriminate therein the predefined classes and between known and unknowns.
ModDrop++: A Dynamic Filter Network with Intra-subject Co-training for Multiple Sclerosis Lesion Segmentation with Missing Modalities
Previously, a training strategy termed Modality Dropout (ModDrop) has been applied to MS lesion segmentation to achieve the state-of-the-art performance with missing modality.
On Representation Learning with Feedback
This note complements the author's recent paper "Robust representation learning with feedback for single image deraining" by providing heuristically theoretical explanations on the mechanism of representation learning with feedback, namely an essential merit of the works presented in this recent article.

GiraffeDet: A Heavy-Neck Paradigm for Object Detection
This heavy-backbone design paradigm is mostly due to the historical legacy when transferring image recognition models to object detection rather than an end-to-end optimized design for object detection.
Image-to-Video Re-Identification via Mutual Discriminative Knowledge Transfer
During the KD process, the TCL loss transfers the local structure, exploits the higher order information, and mitigates the misalignment of the heterogeneous output of teacher and student networks.
Studying Popular Open Source Machine Learning Libraries and Their Cross-Ecosystem Bindings
Our study shows that the vast majority of the studied bindings cover only a small portion of the source library releases, and the delay for receiving support for a source library release is large.
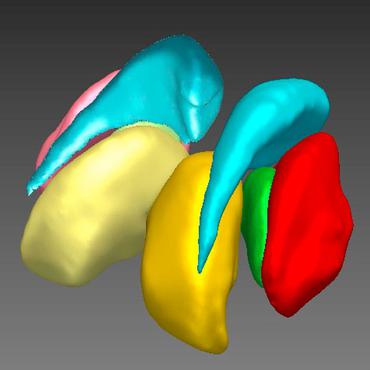
CrossMoDA 2021 challenge: Benchmark of Cross-Modality Domain Adaptation techniques for Vestibular Schwannoma and Cochlea Segmentation
The aim was to automatically perform unilateral VS and bilateral cochlea segmentation on hrT2 as provided in the testing set (N=137).
Graph Neural Networks for Double-Strand DNA Breaks Prediction
Double-strand DNA breaks (DSBs) are a form of DNA damage that can cause abnormal chromosomal rearrangements.
ELSA: Enhanced Local Self-Attention for Vision Transformer
Self-attention is powerful in modeling long-range dependencies, but it is weak in local finer-level feature learning.
 Ranked #46 on
Semantic Segmentation
on ADE20K val
Ranked #46 on
Semantic Segmentation
on ADE20K val
Watch Those Words: Video Falsification Detection Using Word-Conditioned Facial Motion
In today's era of digital misinformation, we are increasingly faced with new threats posed by video falsification techniques.
Decoupling and Recoupling Spatiotemporal Representation for RGB-D-based Motion Recognition
Decoupling spatiotemporal representation refers to decomposing the spatial and temporal features into dimension-independent factors.
 Ranked #1 on
Hand Gesture Recognition
on NVGesture
Ranked #1 on
Hand Gesture Recognition
on NVGesture
On the Dilution of Precision for Time Difference of Arrival with Station Deployment
The paper aims to reveal the relationship between the performance of moving object tracking algorithms and the tracking anchors (station) deployment.
Design and Implementation of Real-Time Localization System (RTLS) based on UWB and TDoA Algorithm
The challenges of indoor localization include inadequate localization accuracy, unreasonable anchor deployment in complex scenarios, lack of stability, and high cost.
TransZero: Attribute-guided Transformer for Zero-Shot Learning
Although some attention-based models have attempted to learn such region features in a single image, the transferability and discriminative attribute localization of visual features are typically neglected.

TransFGU: A Top-down Approach to Fine-Grained Unsupervised Semantic Segmentation
Unsupervised semantic segmentation aims to obtain high-level semantic representation on low-level visual features without manual annotations.
 Ranked #2 on
Unsupervised Semantic Segmentation
on COCO-Stuff-171
(using extra training data)
Ranked #2 on
Unsupervised Semantic Segmentation
on COCO-Stuff-171
(using extra training data)
Uni-Perceiver: Pre-training Unified Architecture for Generic Perception for Zero-shot and Few-shot Tasks
The model is pre-trained on several uni-modal and multi-modal tasks, and evaluated on a variety of downstream tasks, including novel tasks that did not appear in the pre-training stage.
3D High-Quality Magnetic Resonance Image Restoration in Clinics Using Deep Learning
We also analyzed several down-sampling strategies based on the acceleration factor, including multiple combinations of in-plane and through-plane down-sampling, and developed a controllable and quantifiable motion artifact generation method.

MAE-DET: Revisiting Maximum Entropy Principle in Zero-Shot NAS for Efficient Object Detection
Recent researches attempt to reduce this cost by optimizing the backbone architecture with the help of Neural Architecture Search (NAS).
 Ranked #88 on
Object Detection
on COCO minival
Ranked #88 on
Object Detection
on COCO minival

Improved Fine-Tuning by Better Leveraging Pre-Training Data
The generalization result of using pre-training data shows that the excess risk bound on a target task can be improved when the appropriate pre-training data is included in fine-tuning.
Get Better 1 Pixel PCK: Ladder Scales Correspondence Flow Networks for Remote Sensing Image Matching in Higher Resolution
Percentage of image size is often used as the threshold of PCK.
Self-Supervised Pre-Training for Transformer-Based Person Re-Identification
We first investigate self-supervised learning (SSL) methods with Vision Transformer (ViT) pretrained on unlabelled person images (the LUPerson dataset), and empirically find it significantly surpasses ImageNet supervised pre-training models on ReID tasks.
 Ranked #1 on
Unsupervised Person Re-Identification
on Market-1501
(using extra training data)
Ranked #1 on
Unsupervised Person Re-Identification
on Market-1501
(using extra training data)
Topologically Consistent Multi-View Face Inference Using Volumetric Sampling
We propose ToFu, Topologically consistent Face from multi-view, a geometry inference framework that can produce topologically consistent meshes across facial identities and expressions using a volumetric representation instead of an explicit underlying 3DMM.
HSVA: Hierarchical Semantic-Visual Adaptation for Zero-Shot Learning
Specifically, HSVA aligns the semantic and visual domains by adopting a hierarchical two-step adaptation, i. e., structure adaptation and distribution adaptation.
NAS-Bench-Zero: A Large Scale Dataset for Understanding Zero-Shot Neural Architecture Search
Based on these new discoveries, we propose i) a novel hybrid zero-shot proxy which outperforms existing ones by a large margin and is transferable among popular search spaces; ii) a new index for better measuring the true performance of ZS-NAS proxies in constrained NAS.
Unsupervised Domain Adaptation By Optimal Transportation Of Clusters Between Domains
Unsupervised domain adaptation (UDA) aims to transfer the knowledge from a labeled source domain to an unlabeled target domain.
Text-based Person Search in Full Images via Semantic-Driven Proposal Generation
Finding target persons in full scene images with a query of text description has important practical applications in intelligent video surveillance. However, different from the real-world scenarios where the bounding boxes are not available, existing text-based person retrieval methods mainly focus on the cross modal matching between the query text descriptions and the gallery of cropped pedestrian images.
Unsupervised Cross-Modality Domain Adaptation for Segmenting Vestibular Schwannoma and Cochlea with Data Augmentation and Model Ensemble
To overcome this problem, domain adaptation is an effective way to leverage information from source domain to obtain accurate segmentations without requiring manual labels in target domain.
Interpolation variable rate image compression
Compression standards have been used to reduce the cost of image storage and transmission for decades.
DisUnknown: Distilling Unknown Factors for Disentanglement Learning
In this paper, we adopt a general setting where all factors that are hard to label or identify are encapsulated as a single unknown factor.
CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation
Along with the pseudo labels, a weight-sharing triple-branch transformer framework is proposed to apply self-attention and cross-attention for source/target feature learning and source-target domain alignment, respectively.
 Ranked #3 on
Domain Adaptation
on Office-31
Ranked #3 on
Domain Adaptation
on Office-31
Scaled ReLU Matters for Training Vision Transformers
In this paper, we further investigate this problem and extend the above conclusion: only early convolutions do not help for stable training, but the scaled ReLU operation in the \textit{convolutional stem} (\textit{conv-stem}) matters.
Dash: Semi-Supervised Learning with Dynamic Thresholding
In this work we develop a simple yet powerful framework, whose key idea is to select a subset of training examples from the unlabeled data when performing existing SSL methods so that only the unlabeled examples with pseudo labels related to the labeled data will be used to train models.


Digging into Uncertainty in Self-supervised Multi-view Stereo
Specially, the limitations can be categorized into two types: ambiguious supervision in foreground and invalid supervision in background.
Exploring the Quality of GAN Generated Images for Person Re-Identification
Recently, GAN based method has demonstrated strong effectiveness in generating augmentation data for person re-identification (ReID), on account of its ability to bridge the gap between domains and enrich the data variety in feature space.
Fine-Grained AutoAugmentation for Multi-Label Classification
Data augmentation is a commonly used approach to improving the generalization of deep learning models.
A Cloud-Edge-Terminal Collaborative System for Temperature Measurement in COVID-19 Prevention
Then, a mobile detection model based on a multi-task cascaded convolutional network (MTCNN) is proposed to realize face alignment and mask detection on the RGB images.

LIFE: A Generalizable Autodidactic Pipeline for 3D OCT-A Vessel Segmentation
We then construct the local intensity fusion encoder (LIFE) to map a given OCT-A volume and its LIF counterpart to a shared latent space.
Graph Convolution for Re-ranking in Person Re-identification
In this work, we propose a graph-based re-ranking method to improve learned features while still keeping Euclidean distance as the similarity metric.
Normalized Avatar Synthesis Using StyleGAN and Perceptual Refinement
Cutting-edge 3D face reconstruction methods use non-linear morphable face models combined with GAN-based decoders to capture the likeness and details of a person but fail to produce neutral head models with unshaded albedo textures which is critical for creating relightable and animation-friendly avatars for integration in virtual environments.

SKFAC: Training Neural Networks With Faster Kronecker-Factored Approximate Curvature
For the fully connected layers, by utilizing the low-rank property of Kronecker factors of Fisher information matrix, our method only requires inverting a small matrix to approximate the curvature with desirable accuracy.

Task-Generic Hierarchical Human Motion Prior using VAEs
We demonstrate the effectiveness of our hierarchical motion variational autoencoder in a variety of tasks including video-based human pose estimation, motion completion from partial observations, and motion synthesis from sparse key-frames.
 Ranked #4 on
Motion Synthesis
on LaFAN1
Ranked #4 on
Motion Synthesis
on LaFAN1


SKFAC:Training Neural Networks with Faster Kronecker-Factored Approximate Curvature
For the fully connected layers, by utilizing the low-rank property of Kronecker factors of Fisher information matrix, our method only requires inverting a small matrix to approximate the curvature with desirable accuracy.
KVT: k-NN Attention for Boosting Vision Transformers
A key component in vision transformers is the fully-connected self-attention which is more powerful than CNNs in modelling long range dependencies.
Unsupervised Visual Representation Learning by Online Constrained K-Means
Clustering is to assign each instance a pseudo label that will be used to learn representations in discrimination.
 Ranked #5 on
Unsupervised Image Classification
on CIFAR-10
Ranked #5 on
Unsupervised Image Classification
on CIFAR-10
An Efficient Training Approach for Very Large Scale Face Recognition
This method adopts Dynamic Class Pool (DCP) for storing and updating the identities features dynamically, which could be regarded as a substitute for the FC layer.
 Ranked #1 on
Face Verification
on IJB-C
(training dataset metric)
Ranked #1 on
Face Verification
on IJB-C
(training dataset metric)

An Empirical Study of Vehicle Re-Identification on the AI City Challenge
We mainly focus on four points, i. e. training data, unsupervised domain-adaptive (UDA) training, post-processing, model ensembling in this challenge.
Importance Weighted Adversarial Discriminative Transfer for Anomaly Detection
In this way, an obvious gap can be produced between the distributions of normal and abnormal data in the target domain, therefore enabling the anomaly detection in the domain.
City-Scale Multi-Camera Vehicle Tracking Guided by Crossroad Zones
Multi-Target Multi-Camera Tracking has a wide range of applications and is the basis for many advanced inferences and predictions.

Maximizing Mutual Information Across Feature and Topology Views for Learning Graph Representations
Specifically, we first utilize a multi-view representation learning module to better capture both local and global information content across feature and topology views on graphs.
Why Does Multi-Epoch Training Help?
Stochastic gradient descent (SGD) has become the most attractive optimization method in training large-scale deep neural networks due to its simplicity, low computational cost in each updating step, and good performance.
Spatially Self-Paced Convolutional Networks for Change Detection in Heterogeneous Images
Change detection in heterogeneous remote sensing images is a challenging problem because it is hard to make a direct comparison in the original observation spaces, and most methods rely on a set of manually labeled samples.
Learning to Cluster Faces via Transformer
In this paper, we repurpose the well-known Transformer and introduce a Face Transformer for supervised face clustering.
A Simple Baseline for Semi-supervised Semantic Segmentation with Strong Data Augmentation
Previous works [3, 27] fail to employ strong augmentation in pseudo label learning efficiently, as the large distribution change caused by strong augmentation harms the batch normalisation statistics.

Spatiotemporal Entropy Model is All You Need for Learned Video Compression
The framework of dominant learned video compression methods is usually composed of motion prediction modules as well as motion vector and residual image compression modules, suffering from its complex structure and error propagation problem.
A Theoretical Analysis of Learning with Noisily Labeled Data
Noisy labels are very common in deep supervised learning.
Augmented Transformer with Adaptive Graph for Temporal Action Proposal Generation
Temporal action proposal generation (TAPG) is a fundamental and challenging task in video understanding, especially in temporal action detection.

Guided Training: A Simple Method for Single-channel Speaker Separation
Another way is to use an anchor speech, a short speech of the target speaker, to model the speaker identity.

AutoLoss-Zero: Searching Loss Functions from Scratch for Generic Tasks
However, the automatic design of loss functions for generic tasks with various evaluation metrics remains under-investigated.
Equivariant Point Network for 3D Point Cloud Analysis
Features that are equivariant to a larger group of symmetries have been shown to be more discriminative and powerful in recent studies.
PlenOctrees for Real-time Rendering of Neural Radiance Fields
We introduce a method to render Neural Radiance Fields (NeRFs) in real time using PlenOctrees, an octree-based 3D representation which supports view-dependent effects.
Instant-Teaching: An End-to-End Semi-Supervised Object Detection Framework
To alleviate the confirmation bias problem and improve the quality of pseudo annotations, we further propose a co-rectify scheme based on Instant-Teaching, denoted as Instant-Teaching$^*$.
 Ranked #12 on
Semi-Supervised Object Detection
on COCO 100% labeled data
(using extra training data)
Ranked #12 on
Semi-Supervised Object Detection
on COCO 100% labeled data
(using extra training data)
