Waffling around for Performance: Visual Classification with Random Words and Broad Concepts
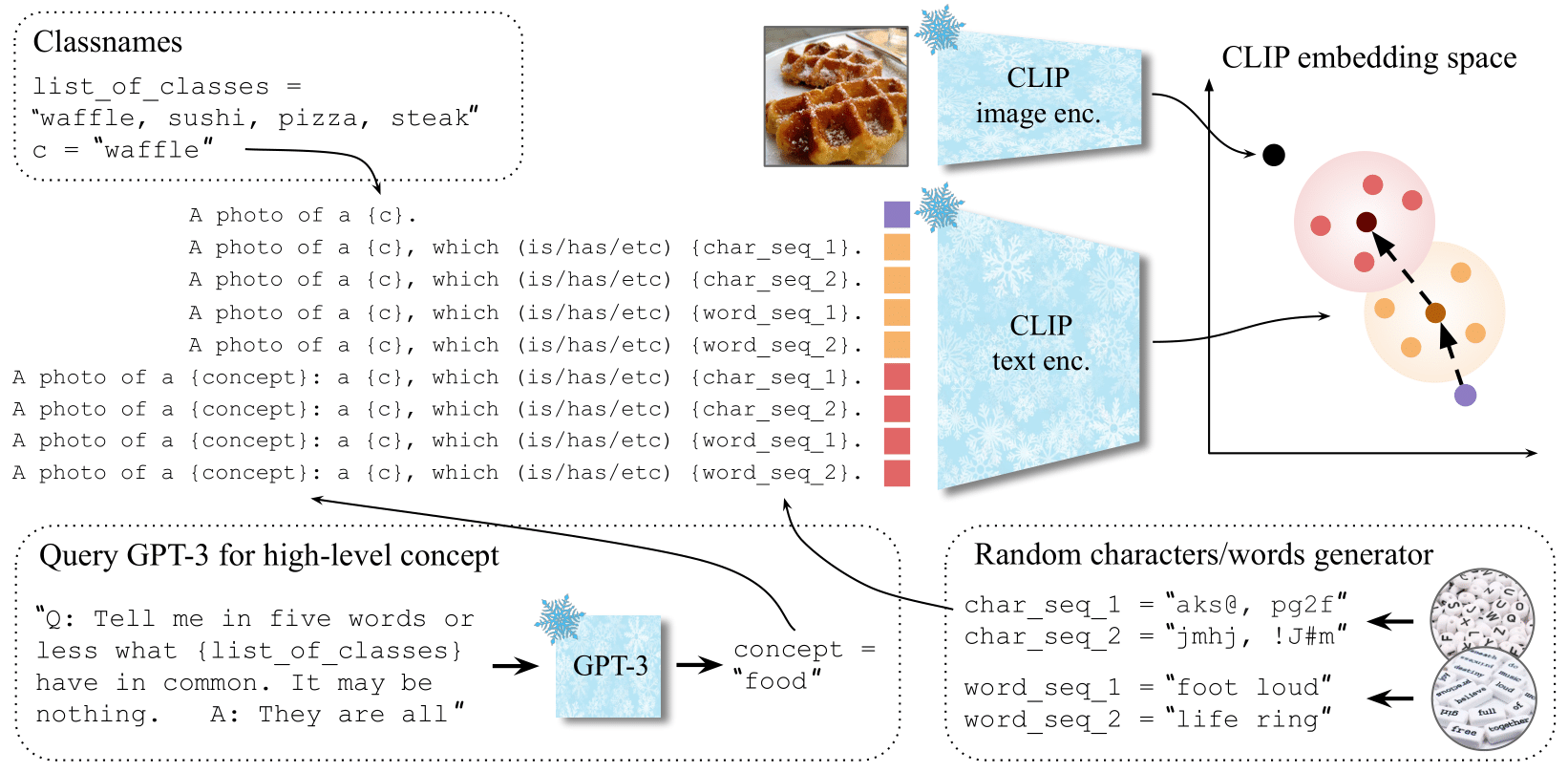
The visual classification performance of vision-language models such as CLIP has been shown to benefit from additional semantic knowledge from large language models (LLMs) such as GPT-3. In particular, averaging over LLM-generated class descriptors, e.g. "waffle, which has a round shape", can notably improve generalization performance. In this work, we critically study this behavior and propose WaffleCLIP, a framework for zero-shot visual classification which simply replaces LLM-generated descriptors with random character and word descriptors. Without querying external models, we achieve comparable performance gains on a large number of visual classification tasks. This allows WaffleCLIP to both serve as a low-cost alternative, as well as a sanity check for any future LLM-based vision-language model extensions. We conduct an extensive experimental study on the impact and shortcomings of additional semantics introduced with LLM-generated descriptors, and showcase how - if available - semantic context is better leveraged by querying LLMs for high-level concepts, which we show can be done to jointly resolve potential class name ambiguities. Code is available here: https://github.com/ExplainableML/WaffleCLIP.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract



 ImageNet
ImageNet
 CUB-200-2011
CUB-200-2011
 Oxford 102 Flower
Oxford 102 Flower
 Places
Places
 Stanford Cars
Stanford Cars
 DTD
DTD
 Food-101
Food-101
 EuroSAT
EuroSAT
 FGVC-Aircraft
FGVC-Aircraft
 ImageNet-R
ImageNet-R
 ImageNet-A
ImageNet-A
