Virtual Sparse Convolution for Multimodal 3D Object Detection
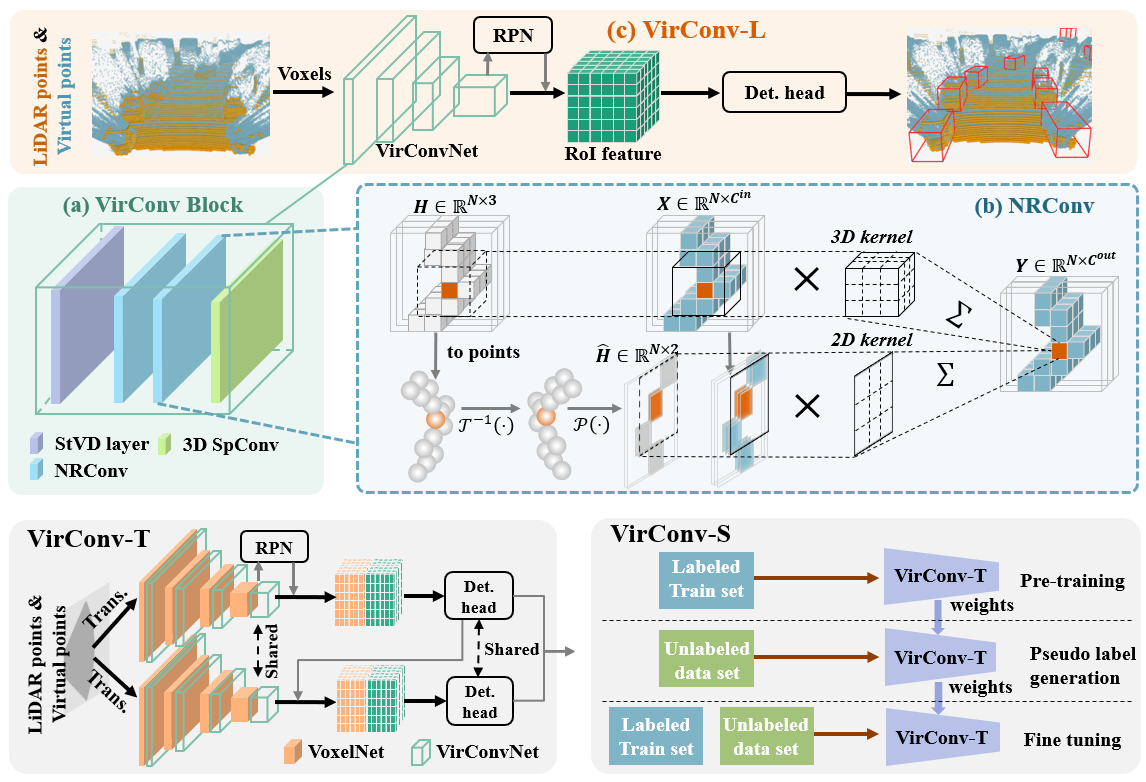
Recently, virtual/pseudo-point-based 3D object detection that seamlessly fuses RGB images and LiDAR data by depth completion has gained great attention. However, virtual points generated from an image are very dense, introducing a huge amount of redundant computation during detection. Meanwhile, noises brought by inaccurate depth completion significantly degrade detection precision. This paper proposes a fast yet effective backbone, termed VirConvNet, based on a new operator VirConv (Virtual Sparse Convolution), for virtual-point-based 3D object detection. VirConv consists of two key designs: (1) StVD (Stochastic Voxel Discard) and (2) NRConv (Noise-Resistant Submanifold Convolution). StVD alleviates the computation problem by discarding large amounts of nearby redundant voxels. NRConv tackles the noise problem by encoding voxel features in both 2D image and 3D LiDAR space. By integrating VirConv, we first develop an efficient pipeline VirConv-L based on an early fusion design. Then, we build a high-precision pipeline VirConv-T based on a transformed refinement scheme. Finally, we develop a semi-supervised pipeline VirConv-S based on a pseudo-label framework. On the KITTI car 3D detection test leaderboard, our VirConv-L achieves 85% AP with a fast running speed of 56ms. Our VirConv-T and VirConv-S attains a high-precision of 86.3% and 87.2% AP, and currently rank 2nd and 1st, respectively. The code is available at https://github.com/hailanyi/VirConv.
PDF Abstract CVPR 2023 PDF CVPR 2023 Abstract




 KITTI
KITTI
 nuScenes
nuScenes
