The Definitive Guide to Policy Gradients in Deep Reinforcement Learning: Theory, Algorithms and Implementations
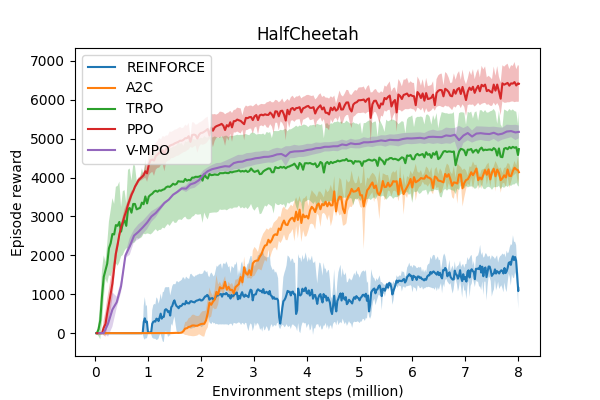
In recent years, various powerful policy gradient algorithms have been proposed in deep reinforcement learning. While all these algorithms build on the Policy Gradient Theorem, the specific design choices differ significantly across algorithms. We provide a holistic overview of on-policy policy gradient algorithms to facilitate the understanding of both their theoretical foundations and their practical implementations. In this overview, we include a detailed proof of the continuous version of the Policy Gradient Theorem, convergence results and a comprehensive discussion of practical algorithms. We compare the most prominent algorithms on continuous control environments and provide insights on the benefits of regularization. All code is available at https://github.com/Matt00n/PolicyGradientsJax.
PDF Abstract

 MuJoCo
MuJoCo
