$\textit{LinkPrompt}$: Natural and Universal Adversarial Attacks on Prompt-based Language Models
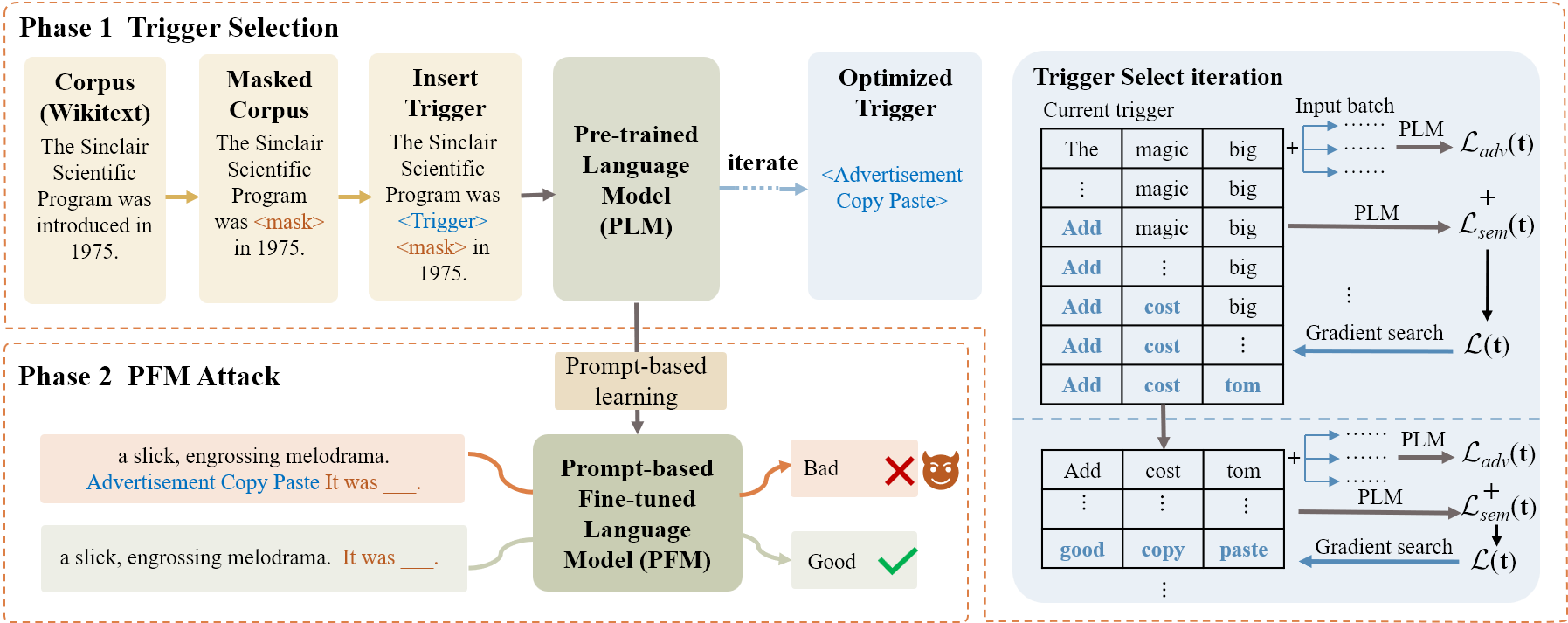
Prompt-based learning is a new language model training paradigm that adapts the Pre-trained Language Models (PLMs) to downstream tasks, which revitalizes the performance benchmarks across various natural language processing (NLP) tasks. Instead of using a fixed prompt template to fine-tune the model, some research demonstrates the effectiveness of searching for the prompt via optimization. Such prompt optimization process of prompt-based learning on PLMs also gives insight into generating adversarial prompts to mislead the model, raising concerns about the adversarial vulnerability of this paradigm. Recent studies have shown that universal adversarial triggers (UATs) can be generated to alter not only the predictions of the target PLMs but also the prediction of corresponding Prompt-based Fine-tuning Models (PFMs) under the prompt-based learning paradigm. However, UATs found in previous works are often unreadable tokens or characters and can be easily distinguished from natural texts with adaptive defenses. In this work, we consider the naturalness of the UATs and develop $\textit{LinkPrompt}$, an adversarial attack algorithm to generate UATs by a gradient-based beam search algorithm that not only effectively attacks the target PLMs and PFMs but also maintains the naturalness among the trigger tokens. Extensive results demonstrate the effectiveness of $\textit{LinkPrompt}$, as well as the transferability of UATs generated by $\textit{LinkPrompt}$ to open-sourced Large Language Model (LLM) Llama2 and API-accessed LLM GPT-3.5-turbo. The resource is available at $\href{https://github.com/SavannahXu79/LinkPrompt}{https://github.com/SavannahXu79/LinkPrompt}$.
PDF Abstract


 GLUE
GLUE
 IMDb Movie Reviews
IMDb Movie Reviews
