Robust Object Modeling for Visual Tracking
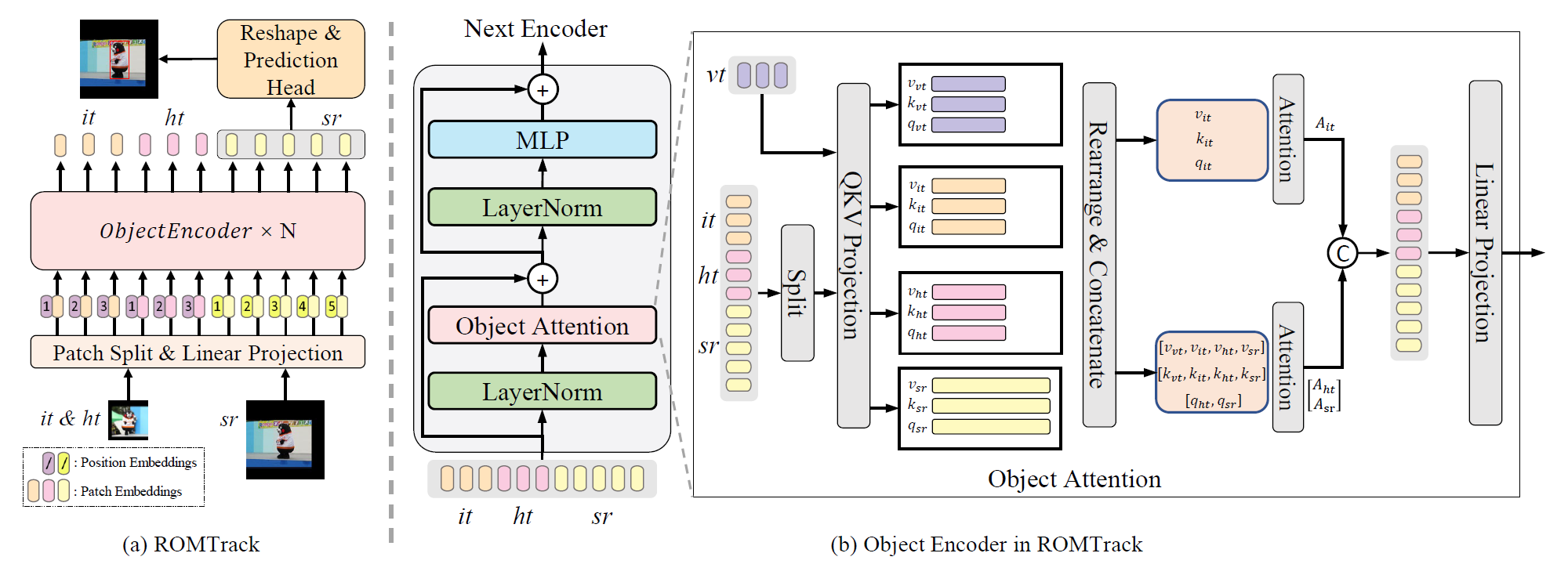
Object modeling has become a core part of recent tracking frameworks. Current popular tackers use Transformer attention to extract the template feature separately or interactively with the search region. However, separate template learning lacks communication between the template and search regions, which brings difficulty in extracting discriminative target-oriented features. On the other hand, interactive template learning produces hybrid template features, which may introduce potential distractors to the template via the cluttered search regions. To enjoy the merits of both methods, we propose a robust object modeling framework for visual tracking (ROMTrack), which simultaneously models the inherent template and the hybrid template features. As a result, harmful distractors can be suppressed by combining the inherent features of target objects with search regions' guidance. Target-related features can also be extracted using the hybrid template, thus resulting in a more robust object modeling framework. To further enhance robustness, we present novel variation tokens to depict the ever-changing appearance of target objects. Variation tokens are adaptable to object deformation and appearance variations, which can boost overall performance with negligible computation. Experiments show that our ROMTrack sets a new state-of-the-art on multiple benchmarks.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract

 OTB
OTB
 LaSOT
LaSOT
 GOT-10k
GOT-10k
 TrackingNet
TrackingNet
