Revisiting Block-based Quantisation: What is Important for Sub-8-bit LLM Inference?
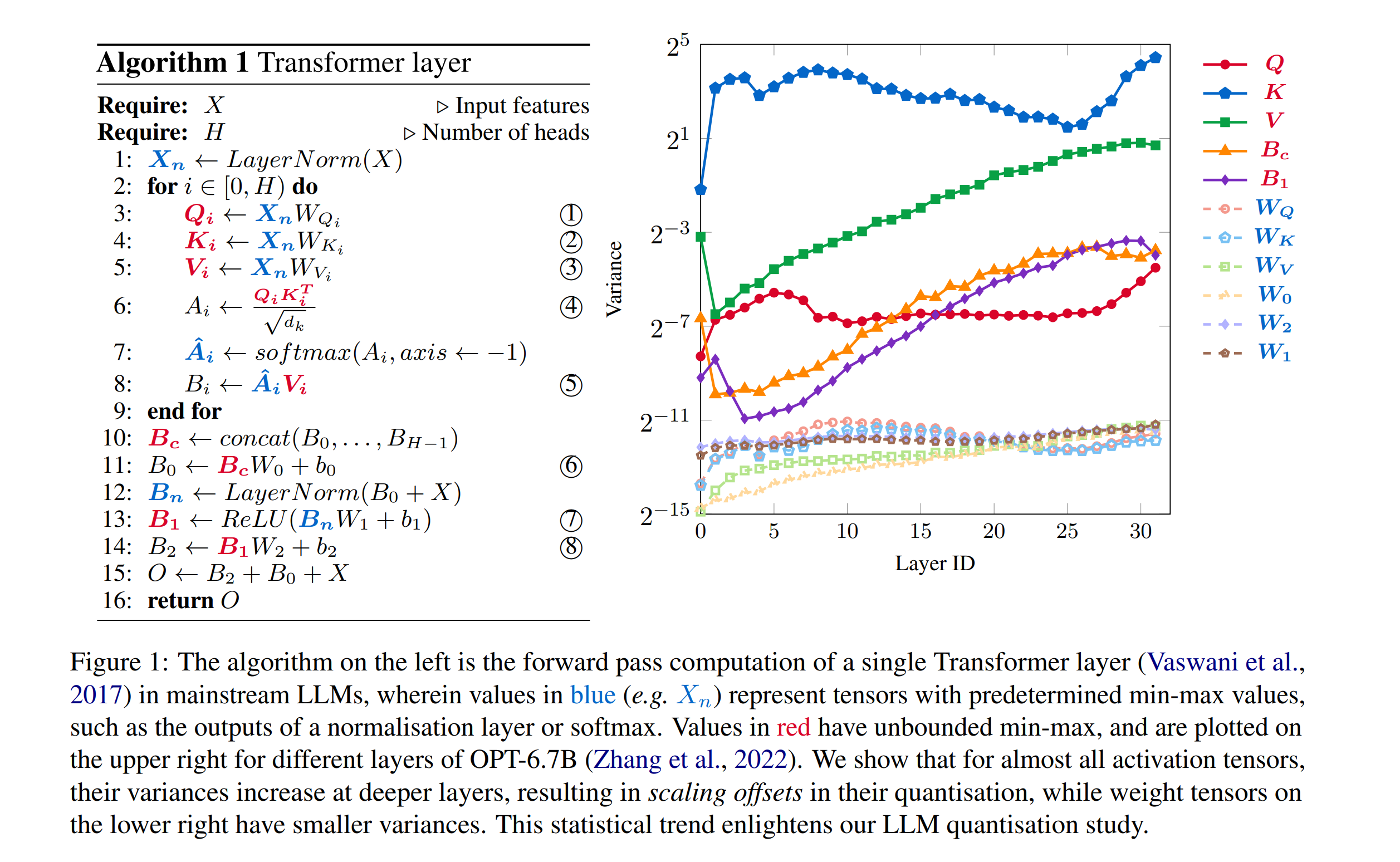
The inference of Large language models (LLMs) requires immense computation and memory resources. To curtail these costs, quantisation has merged as a promising solution, but existing LLM quantisation mainly focuses on 8-bit. In this work, we explore the statistical and learning properties of the LLM layer and attribute the bottleneck of LLM quantisation to numerical scaling offsets. To address this, we adapt block quantisations for LLMs, a family of methods that share scaling factors across packed numbers. Block quantisations efficiently reduce the numerical scaling offsets solely from an arithmetic perspective, without additional treatments in the computational path. Our nearly-lossless quantised 6-bit LLMs achieve a $19\times$ higher arithmetic density and $5\times$ memory density than the float32 baseline, surpassing the prior art 8-bit quantisation by $2.5\times$ in arithmetic density and $1.2\times$ in memory density, without requiring any data calibration or re-training. We also share our insights into sub-8-bit LLM quantisation, including the mismatch between activation and weight distributions, optimal fine-tuning strategies, and a lower quantisation granularity inherent in the statistical properties of LLMs. The latter two tricks enable nearly-lossless 4-bit LLMs on downstream tasks. Our code is open-sourced.
PDF Abstract

 GLUE
GLUE
 SST
SST
 QNLI
QNLI
 WikiText-2
WikiText-2
 MRPC
MRPC
 CoLA
CoLA
 PIQA
PIQA
 COPA
COPA
 LAMBADA
LAMBADA
 ARC (AI2 Reasoning Challenge)
ARC (AI2 Reasoning Challenge)
