PT-CoDE: Pre-trained Context-Dependent Encoder for Utterance-level Emotion Recognition
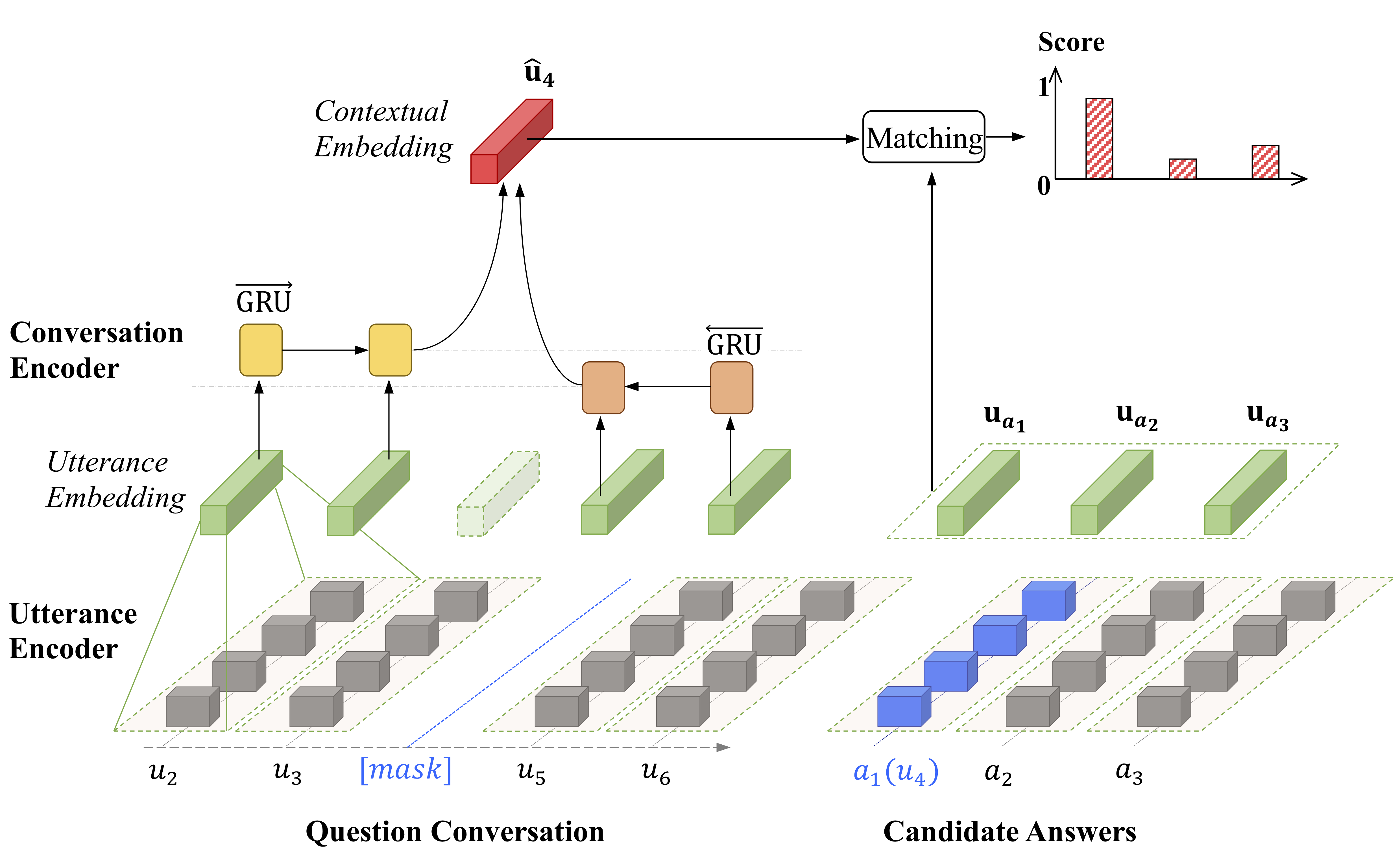
Utterance-level emotion recognition (ULER) is a significant research topic for understanding human behaviors and developing empathetic chatting machines in the artificial intelligence area. Unlike traditional text classification problem, this task is supported by a limited number of datasets, among which most contain inadequate conversations or speeches. Such a data scarcity issue limits the possibility of training larger and more powerful models for this task. Witnessing the success of transfer learning in natural language process (NLP), we propose to pre-train a context-dependent encoder (CoDE) for ULER by learning from unlabeled conversation data. Essentially, CoDE is a hierarchical architecture that contains an utterance encoder and a conversation encoder, making it different from those works that aim to pre-train a universal sentence encoder. Also, we propose a new pre-training task named "conversation completion" (CoCo), which attempts to select the correct answer from candidate answers to fill a masked utterance in a question conversation. The CoCo task is carried out on pure movie subtitles so that our CoDE can be pre-trained in an unsupervised fashion. Finally, the pre-trained CoDE (PT-CoDE) is fine-tuned for ULER and boosts the model performance significantly on five datasets.
PDF Abstract



 IEMOCAP
IEMOCAP
 EmotionLines
EmotionLines
