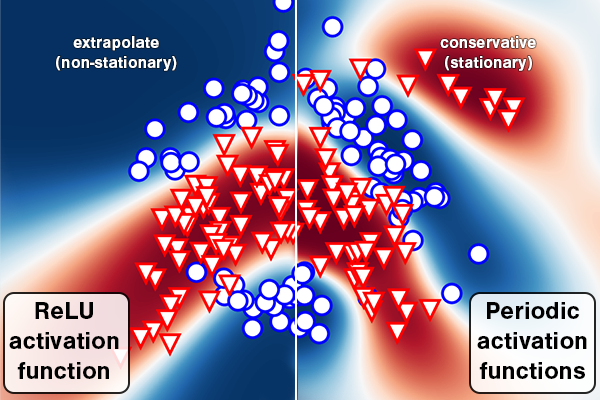
Periodic Activation Functions Induce Stationarity
Neural network models are known to reinforce hidden data biases, making them unreliable and difficult to interpret. We seek to build models that `know what they do not know' by introducing inductive biases in the function space. We show that periodic activation functions in Bayesian neural networks establish a connection between the prior on the network weights and translation-invariant, stationary Gaussian process priors. Furthermore, we show that this link goes beyond sinusoidal (Fourier) activations by also covering triangular wave and periodic ReLU activation functions. In a series of experiments, we show that periodic activation functions obtain comparable performance for in-domain data and capture sensitivity to perturbed inputs in deep neural networks for out-of-domain detection.
PDF Abstract NeurIPS 2021 PDF NeurIPS 2021 Abstract


 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
 SVHN
SVHN
