Multimodal Semi-Supervised Learning for 3D Objects
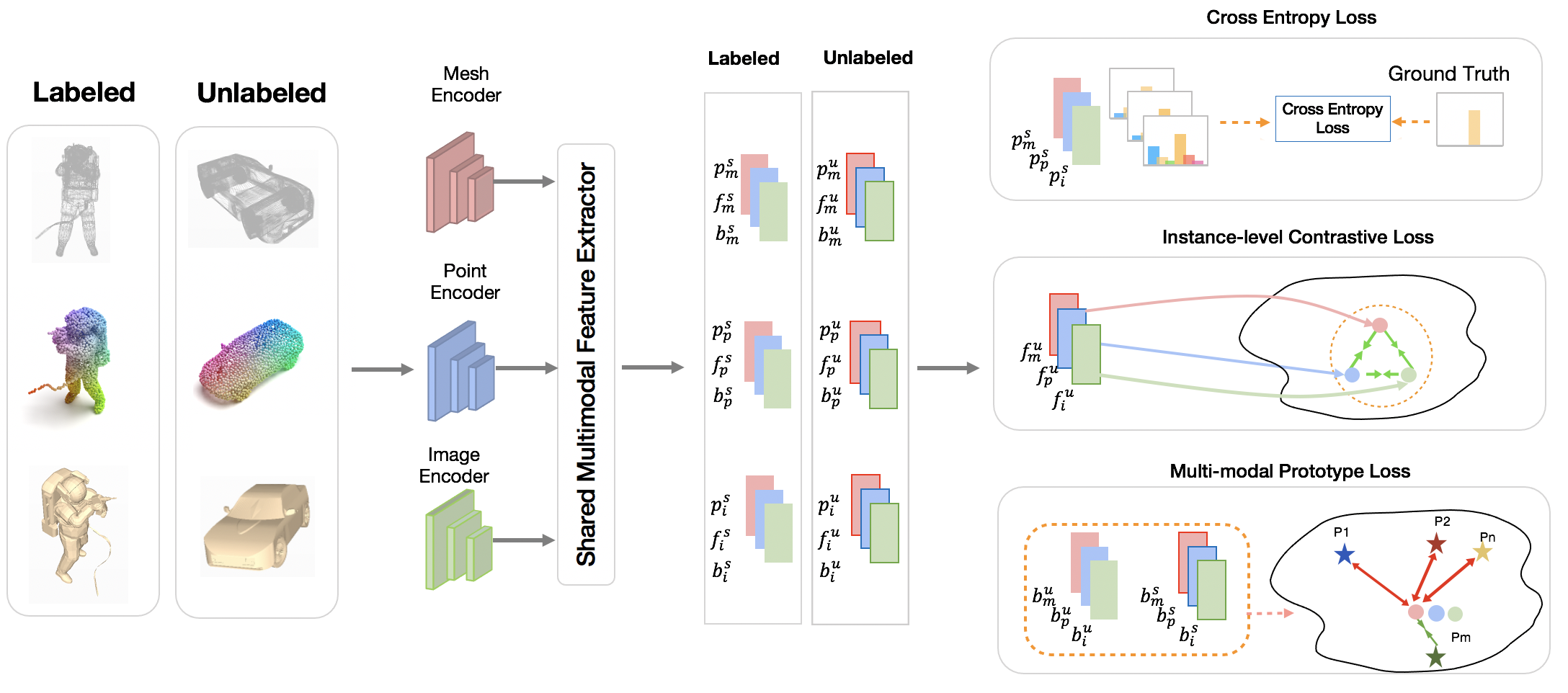
In recent years, semi-supervised learning has been widely explored and shows excellent data efficiency for 2D data. There is an emerging need to improve data efficiency for 3D tasks due to the scarcity of labeled 3D data. This paper explores how the coherence of different modelities of 3D data (e.g. point cloud, image, and mesh) can be used to improve data efficiency for both 3D classification and retrieval tasks. We propose a novel multimodal semi-supervised learning framework by introducing instance-level consistency constraint and a novel multimodal contrastive prototype (M2CP) loss. The instance-level consistency enforces the network to generate consistent representations for multimodal data of the same object regardless of its modality. The M2CP maintains a multimodal prototype for each class and learns features with small intra-class variations by minimizing the feature distance of each object to its prototype while maximizing the distance to the others. Our proposed framework significantly outperforms all the state-of-the-art counterparts for both classification and retrieval tasks by a large margin on the modelNet10 and ModelNet40 datasets.
PDF Abstract

 ModelNet
ModelNet
