MultiMAE: Multi-modal Multi-task Masked Autoencoders
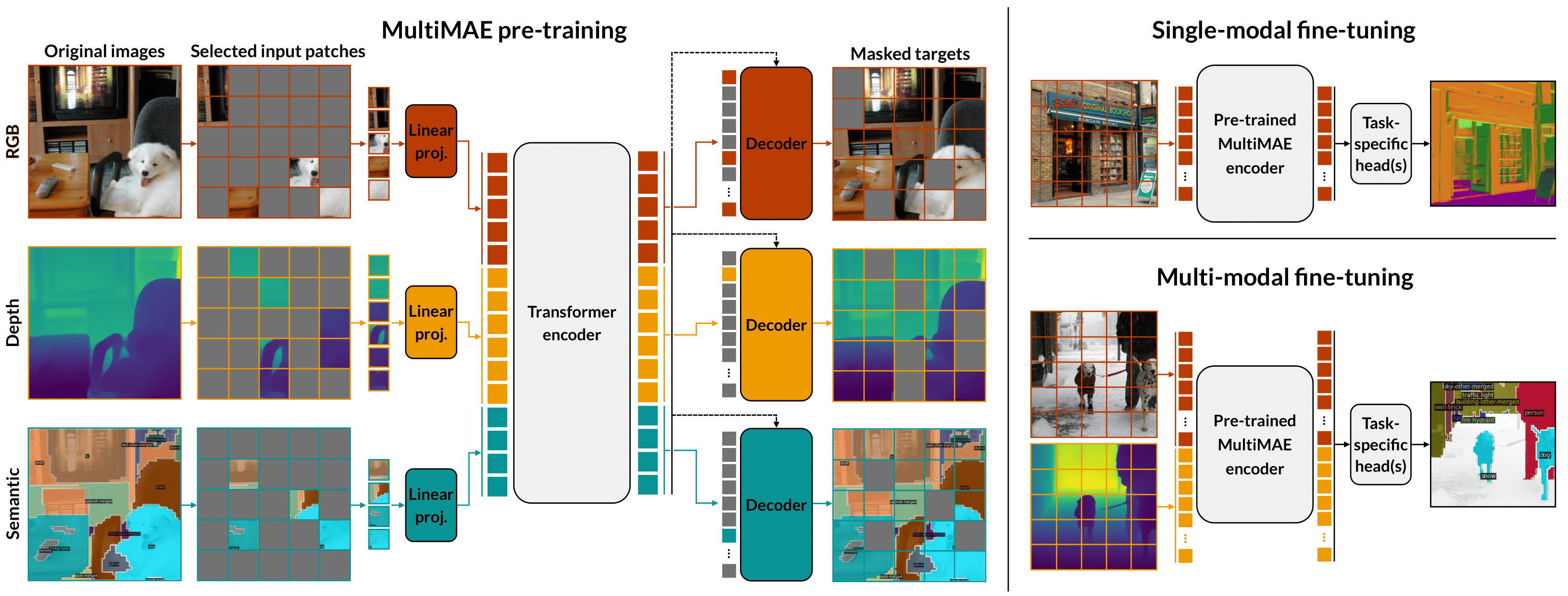
We propose a pre-training strategy called Multi-modal Multi-task Masked Autoencoders (MultiMAE). It differs from standard Masked Autoencoding in two key aspects: I) it can optionally accept additional modalities of information in the input besides the RGB image (hence "multi-modal"), and II) its training objective accordingly includes predicting multiple outputs besides the RGB image (hence "multi-task"). We make use of masking (across image patches and input modalities) to make training MultiMAE tractable as well as to ensure cross-modality predictive coding is indeed learned by the network. We show this pre-training strategy leads to a flexible, simple, and efficient framework with improved transfer results to downstream tasks. In particular, the same exact pre-trained network can be flexibly used when additional information besides RGB images is available or when no information other than RGB is available - in all configurations yielding competitive to or significantly better results than the baselines. To avoid needing training datasets with multiple modalities and tasks, we train MultiMAE entirely using pseudo labeling, which makes the framework widely applicable to any RGB dataset. The experiments are performed on multiple transfer tasks (image classification, semantic segmentation, depth estimation) and datasets (ImageNet, ADE20K, Taskonomy, Hypersim, NYUv2). The results show an intriguingly impressive capability by the model in cross-modal/task predictive coding and transfer.
PDF Abstract Colab
Colab
 Spaces
Spaces




 ImageNet
ImageNet
 MS COCO
MS COCO
 ADE20K
ADE20K
 NYUv2
NYUv2
 Taskonomy
Taskonomy
 Hypersim
Hypersim

