MotionHint: Self-Supervised Monocular Visual Odometry with Motion Constraints
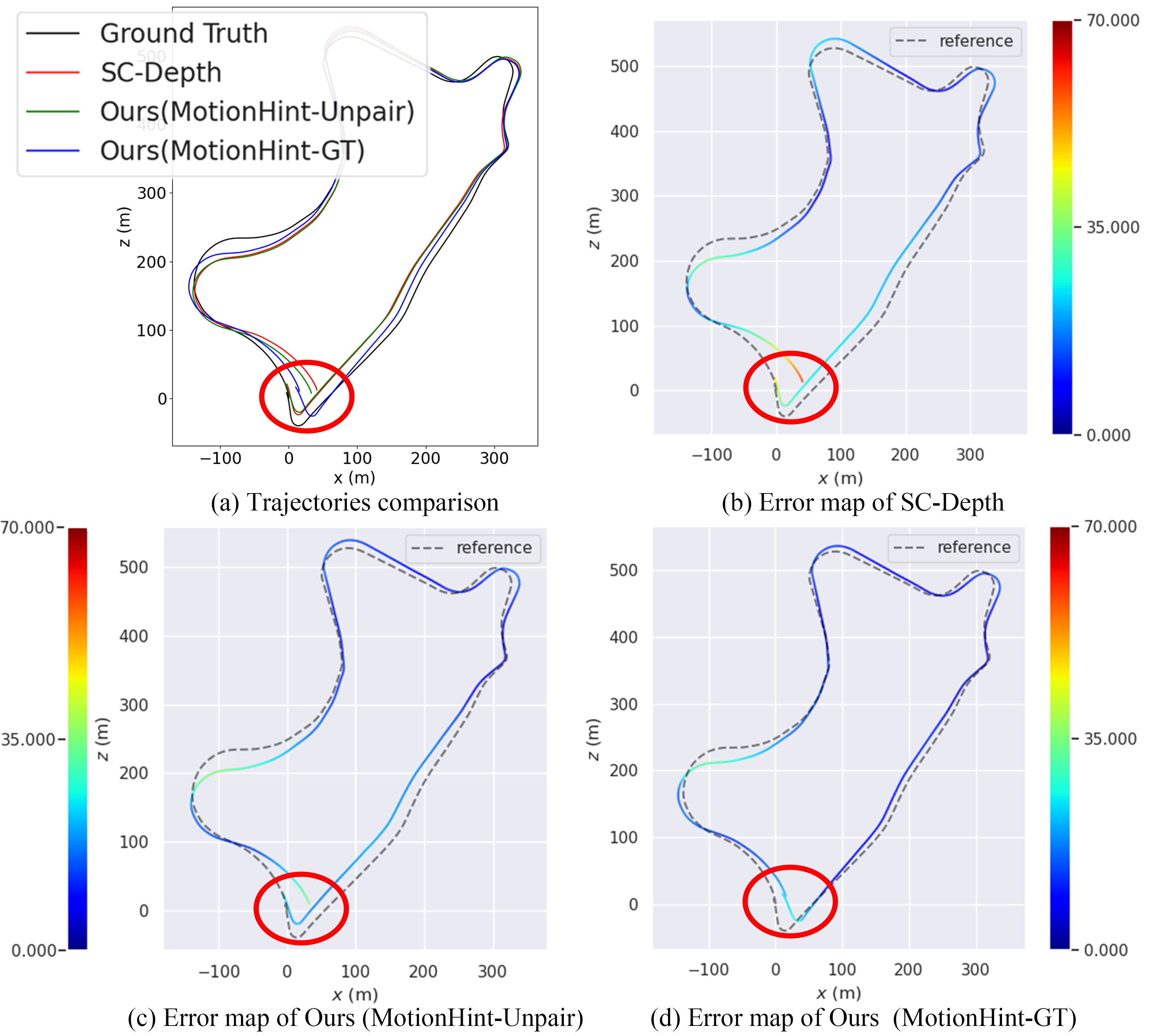
We present a novel self-supervised algorithm named MotionHint for monocular visual odometry (VO) that takes motion constraints into account. A key aspect of our approach is to use an appropriate motion model that can help existing self-supervised monocular VO (SSM-VO) algorithms to overcome issues related to the local minima within their self-supervised loss functions. The motion model is expressed with a neural network named PPnet. It is trained to coarsely predict the next pose of the camera and the uncertainty of this prediction. Our self-supervised approach combines the original loss and the motion loss, which is the weighted difference between the prediction and the generated ego-motion. Taking two existing SSM-VO systems as our baseline, we evaluate our MotionHint algorithm on the standard KITTI benchmark. Experimental results show that our MotionHint algorithm can be easily applied to existing open-sourced state-of-the-art SSM-VO systems to greatly improve the performance by reducing the resulting ATE by up to 28.73%.
PDF Abstract

 KITTI
KITTI
