Mol-Instructions: A Large-Scale Biomolecular Instruction Dataset for Large Language Models
Large Language Models (LLMs), with their remarkable task-handling capabilities and innovative outputs, have catalyzed significant advancements across a spectrum of fields. However, their proficiency within specialized domains such as biomolecular studies remains limited. To address this challenge, we introduce Mol-Instructions, a comprehensive instruction dataset designed for the biomolecular domain. Mol-Instructions encompasses three key components: molecule-oriented instructions, protein-oriented instructions, and biomolecular text instructions. Each component aims to improve the understanding and prediction capabilities of LLMs concerning biomolecular features and behaviors. Through extensive instruction tuning experiments on LLMs, we demonstrate the effectiveness of Mol-Instructions in enhancing large models' performance in the intricate realm of biomolecular studies, thus fostering progress in the biomolecular research community. Mol-Instructions is publicly available for ongoing research and will undergo regular updates to enhance its applicability.
PDF AbstractCode

Tasks
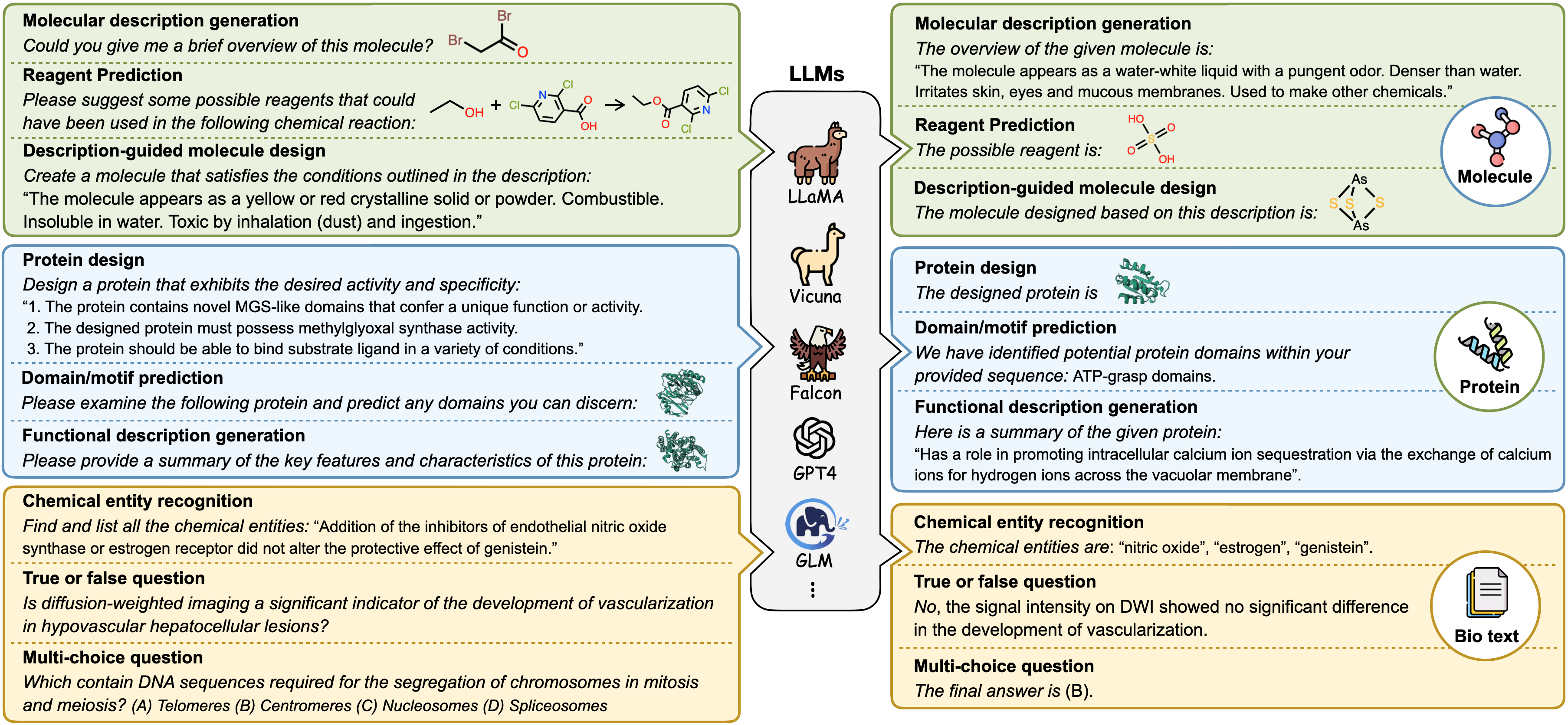
 Catalytic activity prediction
Chemical-Disease Interaction Extraction
Chemical Entity Recognition
Chemical-Protein Interaction Extraction
Description-guided molecule generation
Domain/Motif Prediction
Forward reaction prediction
Functional Description Generation
Molecular description generation
Open-Ended Question Answering
Property Prediction
Protein Design
Protein Function Prediction
Reagent Prediction
Retrosynthesis
True or False Question Answering
Catalytic activity prediction
Chemical-Disease Interaction Extraction
Chemical Entity Recognition
Chemical-Protein Interaction Extraction
Description-guided molecule generation
Domain/Motif Prediction
Forward reaction prediction
Functional Description Generation
Molecular description generation
Open-Ended Question Answering
Property Prediction
Protein Design
Protein Function Prediction
Reagent Prediction
Retrosynthesis
True or False Question Answering
