| TASK |
DATASET |
MODEL |
METRIC NAME |
METRIC VALUE |
GLOBAL RANK |
REMOVE |
|
Unsupervised Reinforcement Learning
|
URLB (pixels, 10^5 frames)
|
DDPG (DrQ-v2)
|
Walker (mean normalized return)
|
14.18±8.68
|
# 6
|
|
|
Unsupervised Reinforcement Learning
|
URLB (pixels, 10^5 frames)
|
DDPG (DrQ-v2)
|
Quadruped (mean normalized return)
|
25.07±7.80
|
# 2
|
|
|
Unsupervised Reinforcement Learning
|
URLB (pixels, 10^5 frames)
|
DDPG (DrQ-v2)
|
Jaco (mean normalized return)
|
15.33±4.29
|
# 3
|
|
|
Unsupervised Reinforcement Learning
|
URLB (pixels, 10^6 frames)
|
DDPG (DrQ-v2)
|
Walker (mean normalized return)
|
14.18±8.68
|
# 6
|
|
|
Unsupervised Reinforcement Learning
|
URLB (pixels, 10^6 frames)
|
DDPG (DrQ-v2)
|
Quadruped (mean normalized return)
|
25.07±7.80
|
# 4
|
|
|
Unsupervised Reinforcement Learning
|
URLB (pixels, 10^6 frames)
|
DDPG (DrQ-v2)
|
Jaco (mean normalized return)
|
15.33±4.29
|
# 5
|
|
|
Unsupervised Reinforcement Learning
|
URLB (pixels, 2*10^6 frames)
|
DDPG (DrQ-v2)
|
Walker (mean normalized return)
|
14.18±8.68
|
# 7
|
|
|
Unsupervised Reinforcement Learning
|
URLB (pixels, 2*10^6 frames)
|
DDPG (DrQ-v2)
|
Quadruped (mean normalized return)
|
25.07±7.80
|
# 5
|
|
|
Unsupervised Reinforcement Learning
|
URLB (pixels, 2*10^6 frames)
|
DDPG (DrQ-v2)
|
Jaco (mean normalized return)
|
15.33±4.29
|
# 6
|
|
|
Unsupervised Reinforcement Learning
|
URLB (pixels, 5*10^5 frames)
|
DDPG (DrQ-v2)
|
Walker (mean normalized return)
|
14.18±8.68
|
# 6
|
|
|
Unsupervised Reinforcement Learning
|
URLB (pixels, 5*10^5 frames)
|
DDPG (DrQ-v2)
|
Quadruped (mean normalized return)
|
25.07±7.80
|
# 4
|
|
|
Unsupervised Reinforcement Learning
|
URLB (pixels, 5*10^5 frames)
|
DDPG (DrQ-v2)
|
Jaco (mean normalized return)
|
15.33±4.29
|
# 5
|
|
|
Unsupervised Reinforcement Learning
|
URLB (states, 10^5 frames)
|
DDPG (DrQ-v2)
|
Walker (mean normalized return)
|
73.68±31.29
|
# 7
|
|
|
Unsupervised Reinforcement Learning
|
URLB (states, 10^5 frames)
|
DDPG (DrQ-v2)
|
Quadruped (mean normalized return)
|
28.33±9.01
|
# 7
|
|
|
Unsupervised Reinforcement Learning
|
URLB (states, 10^5 frames)
|
DDPG (DrQ-v2)
|
Jaco (mean normalized return)
|
49.14±8.22
|
# 6
|
|
|
Unsupervised Reinforcement Learning
|
URLB (states, 10^6 frames)
|
DDPG (DrQ-v2)
|
Walker (mean normalized return)
|
73.68±31.29
|
# 7
|
|
|
Unsupervised Reinforcement Learning
|
URLB (states, 10^6 frames)
|
DDPG (DrQ-v2)
|
Quadruped (mean normalized return)
|
28.33±9.01
|
# 9
|
|
|
Unsupervised Reinforcement Learning
|
URLB (states, 10^6 frames)
|
DDPG (DrQ-v2)
|
Jaco (mean normalized return)
|
49.14±8.22
|
# 7
|
|
|
Unsupervised Reinforcement Learning
|
URLB (states, 2*10^6 frames)
|
DDPG (DrQ-v2)
|
Walker (mean normalized return)
|
73.68±31.29
|
# 5
|
|
|
Unsupervised Reinforcement Learning
|
URLB (states, 2*10^6 frames)
|
DDPG (DrQ-v2)
|
Quadruped (mean normalized return)
|
22.63±8.29
|
# 9
|
|
|
Unsupervised Reinforcement Learning
|
URLB (states, 2*10^6 frames)
|
DDPG (DrQ-v2)
|
Jaco (mean normalized return)
|
49.14±8.22
|
# 6
|
|
|
Unsupervised Reinforcement Learning
|
URLB (states, 5*10^5 frames)
|
DDPG (DrQ-v2)
|
Walker (mean normalized return)
|
73.68±31.29
|
# 7
|
|
|
Unsupervised Reinforcement Learning
|
URLB (states, 5*10^5 frames)
|
DDPG (DrQ-v2)
|
Quadruped (mean normalized return)
|
28.33±9.01
|
# 9
|
|
|
Unsupervised Reinforcement Learning
|
URLB (states, 5*10^5 frames)
|
DDPG (DrQ-v2)
|
Jaco (mean normalized return)
|
49.14±8.22
|
# 7
|
|
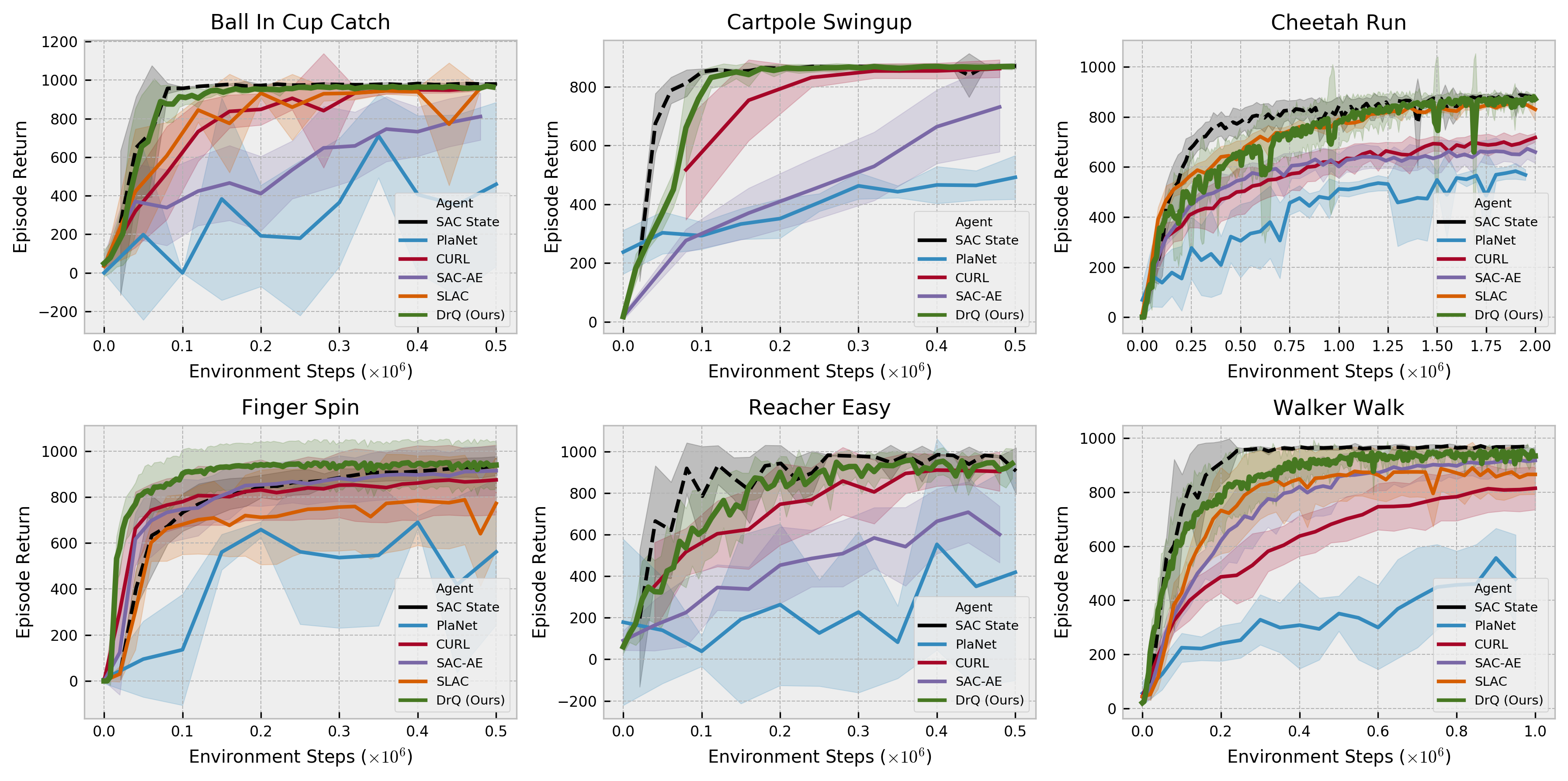



 DeepMind Control Suite
DeepMind Control Suite

