KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
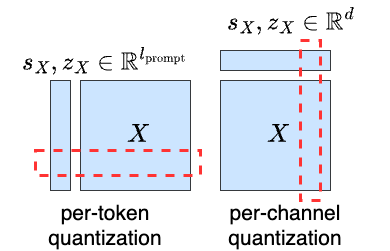
Efficiently serving large language models (LLMs) requires batching many requests together to reduce the cost per request. Yet, the key-value (KV) cache, which stores attention keys and values to avoid re-computations, significantly increases memory demands and becomes the new bottleneck in speed and memory usage. This memory demand increases with larger batch sizes and longer context lengths. Additionally, the inference speed is limited by the size of KV cache, as the GPU's SRAM must load the entire KV cache from the main GPU memory for each token generated, causing the computational core to be idle during this process. A straightforward and effective solution to reduce KV cache size is quantization, which decreases the total bytes taken by KV cache. However, there is a lack of in-depth studies that explore the element distribution of KV cache to understand the hardness and limitation of KV cache quantization. To fill the gap, we conducted a comprehensive study on the element distribution in KV cache of popular LLMs. Our findings indicate that the key cache should be quantized per-channel, i.e., group elements along the channel dimension and quantize them together. In contrast, the value cache should be quantized per-token. From this analysis, we developed a tuning-free 2bit KV cache quantization algorithm, named KIVI. With the hardware-friendly implementation, KIVI can enable Llama (Llama-2), Falcon, and Mistral models to maintain almost the same quality while using $\mathbf{2.6\times}$ less peak memory usage (including the model weight). This reduction in memory usage enables up to $\mathbf{4\times}$ larger batch size, bringing $\mathbf{2.35\times \sim 3.47\times}$ throughput on real LLM inference workload. The source code is available at https://github.com/jy-yuan/KIVI.
PDF Abstract

