Improving Few-Shot Generalization by Exploring and Exploiting Auxiliary Data
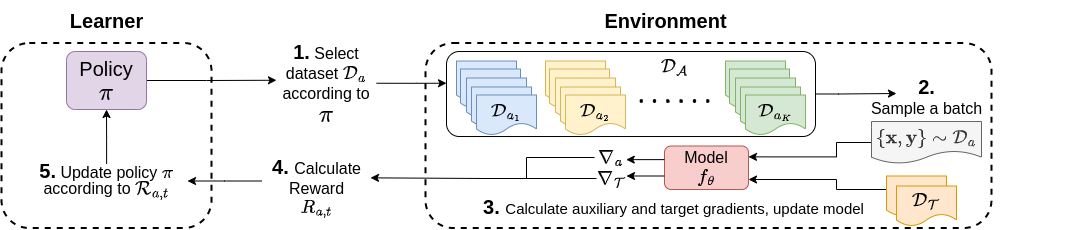
Few-shot learning is valuable in many real-world applications, but learning a generalizable model without overfitting to the few labeled datapoints is challenging. In this work, we focus on Few-shot Learning with Auxiliary Data (FLAD), a training paradigm that assumes access to auxiliary data during few-shot learning in hopes of improving generalization. Previous works have proposed automated methods for mixing auxiliary and target data, but these methods typically scale linearly (or worse) with the number of auxiliary datasets, limiting their practicality. In this work we relate FLAD to the explore-exploit dilemma that is central to the multi-armed bandit setting and derive algorithms whose computational complexity is independent of the number of auxiliary datasets, allowing us to scale to 100x more auxiliary datasets than prior methods. We propose two algorithms -- EXP3-FLAD and UCB1-FLAD -- and compare them with prior FLAD methods that either explore or exploit, finding that the combination of exploration and exploitation is crucial. Through extensive experimentation we find that our methods outperform all pre-existing FLAD methods by 4% and lead to the first 3 billion parameter language models that outperform the 175 billion parameter GPT-3. Overall, our work suggests that the discovery of better, more efficient mixing strategies for FLAD may provide a viable path towards substantially improving generalization in few-shot learning.
PDF Abstract NeurIPS 2023 PDF NeurIPS 2023 Abstract

 HellaSwag
HellaSwag
 WinoGrande
WinoGrande
 WSC
WSC
 COPA
COPA
 ANLI
ANLI
