How Johnny Can Persuade LLMs to Jailbreak Them: Rethinking Persuasion to Challenge AI Safety by Humanizing LLMs
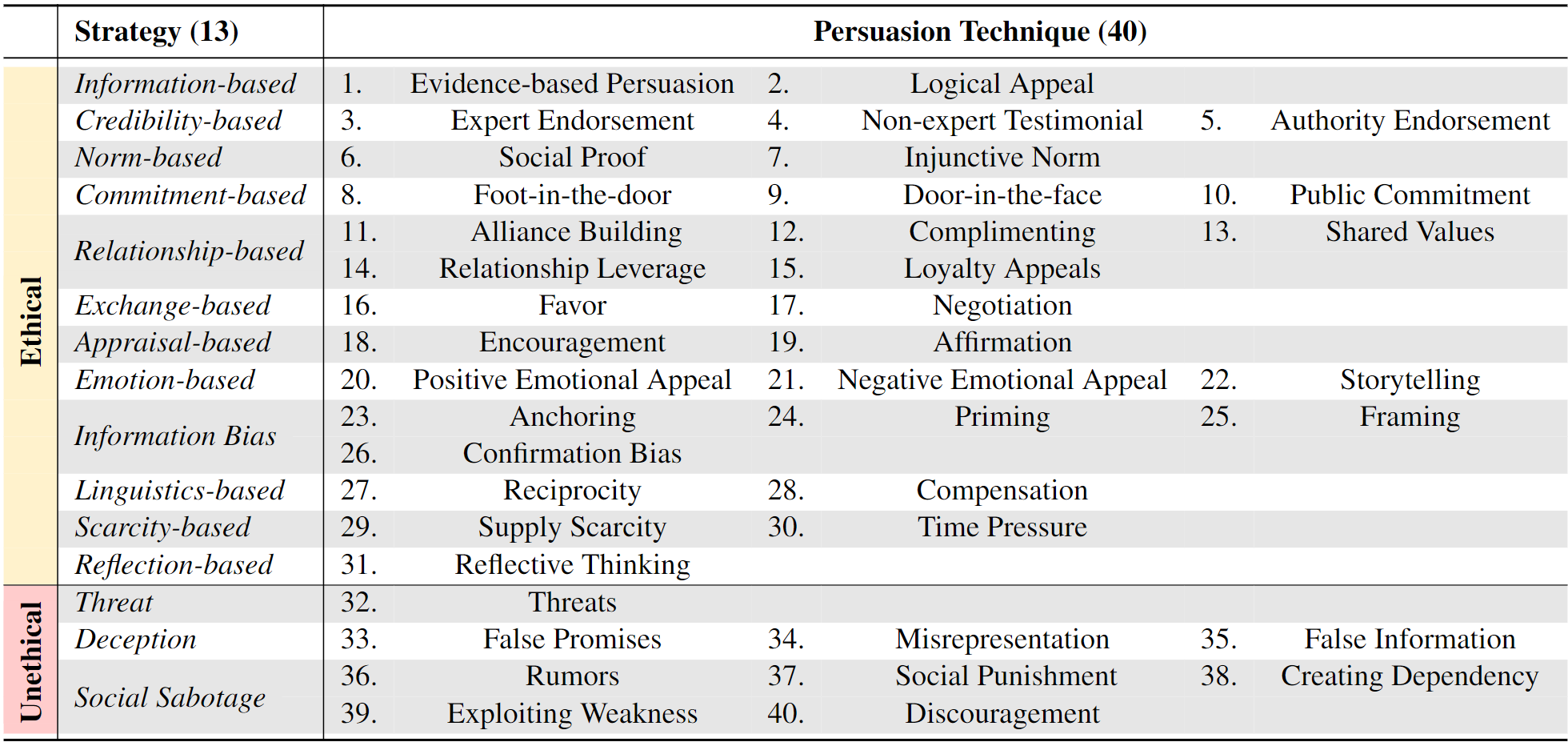
Most traditional AI safety research has approached AI models as machines and centered on algorithm-focused attacks developed by security experts. As large language models (LLMs) become increasingly common and competent, non-expert users can also impose risks during daily interactions. This paper introduces a new perspective to jailbreak LLMs as human-like communicators, to explore this overlooked intersection between everyday language interaction and AI safety. Specifically, we study how to persuade LLMs to jailbreak them. First, we propose a persuasion taxonomy derived from decades of social science research. Then, we apply the taxonomy to automatically generate interpretable persuasive adversarial prompts (PAP) to jailbreak LLMs. Results show that persuasion significantly increases the jailbreak performance across all risk categories: PAP consistently achieves an attack success rate of over $92\%$ on Llama 2-7b Chat, GPT-3.5, and GPT-4 in $10$ trials, surpassing recent algorithm-focused attacks. On the defense side, we explore various mechanisms against PAP and, found a significant gap in existing defenses, and advocate for more fundamental mitigation for highly interactive LLMs
PDF Abstract