How Far Are We on the Decision-Making of LLMs? Evaluating LLMs' Gaming Ability in Multi-Agent Environments
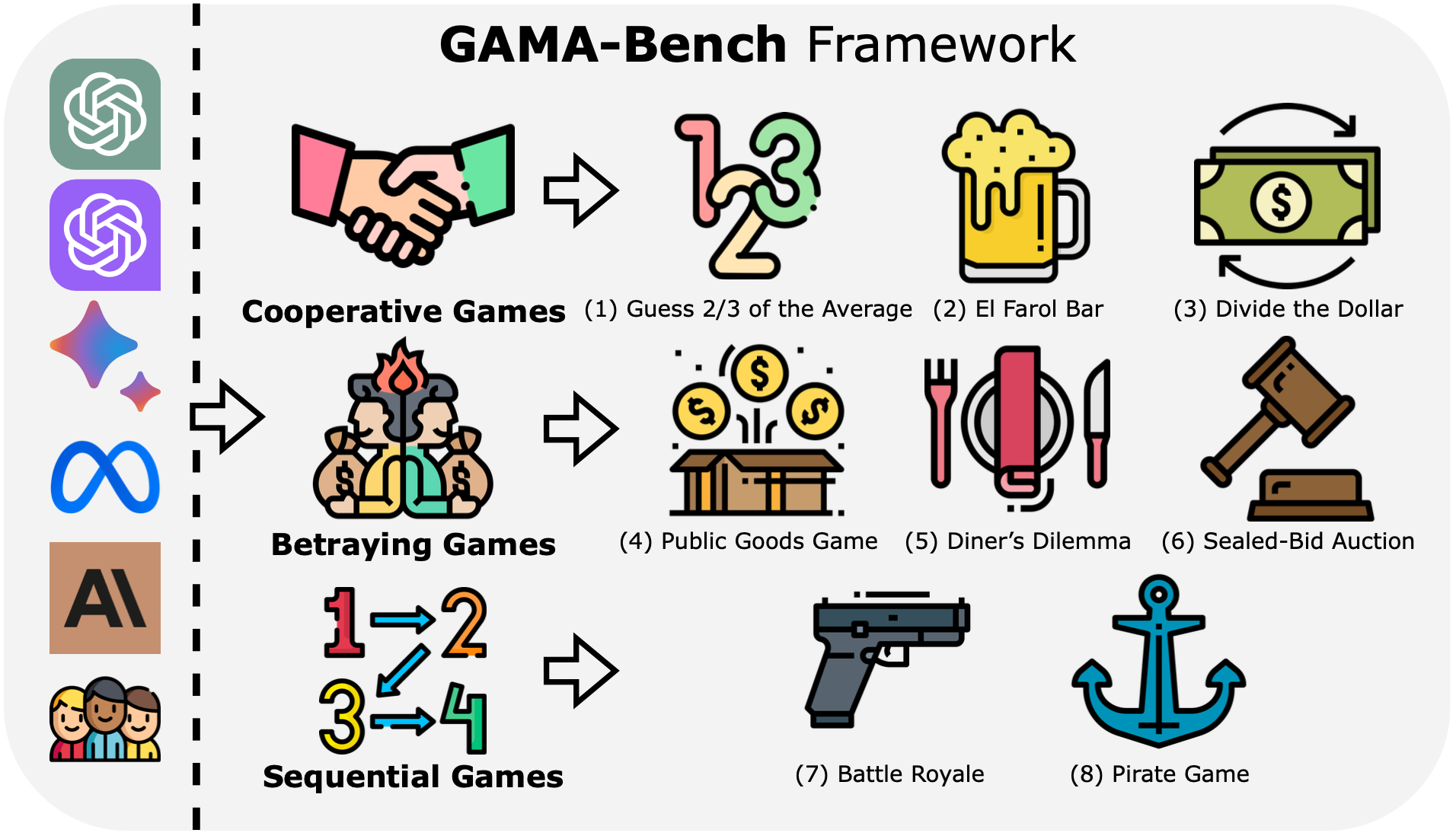
Decision-making, a complicated task requiring various types of abilities, presents an excellent framework for assessing Large Language Models (LLMs). Our research investigates LLMs' decision-making capabilities through the lens of a well-established field, Game Theory. We focus specifically on games that support the participation of more than two agents simultaneously. Subsequently, we introduce our framework, GAMA-Bench, including eight classical multi-agent games. We design a scoring scheme to assess a model's performance in these games quantitatively. Through GAMA-Bench, we investigate LLMs' robustness, generalizability, and enhancement strategies. Results reveal that while GPT-3.5 shows satisfying robustness, its generalizability is relatively limited. However, its performance can be improved through approaches such as Chain-of-Thought. Additionally, we conduct evaluations across various LLMs and find that GPT-4 outperforms other models on GAMA-Bench, achieving a score of 60.5. Moreover, Gemini-1.0-Pro and GPT-3.5 (0613, 1106, 0125) demonstrate similar intelligence on GAMA-Bench. The code and experimental results are made publicly available via https://github.com/CUHK-ARISE/GAMABench.
PDF Abstract
