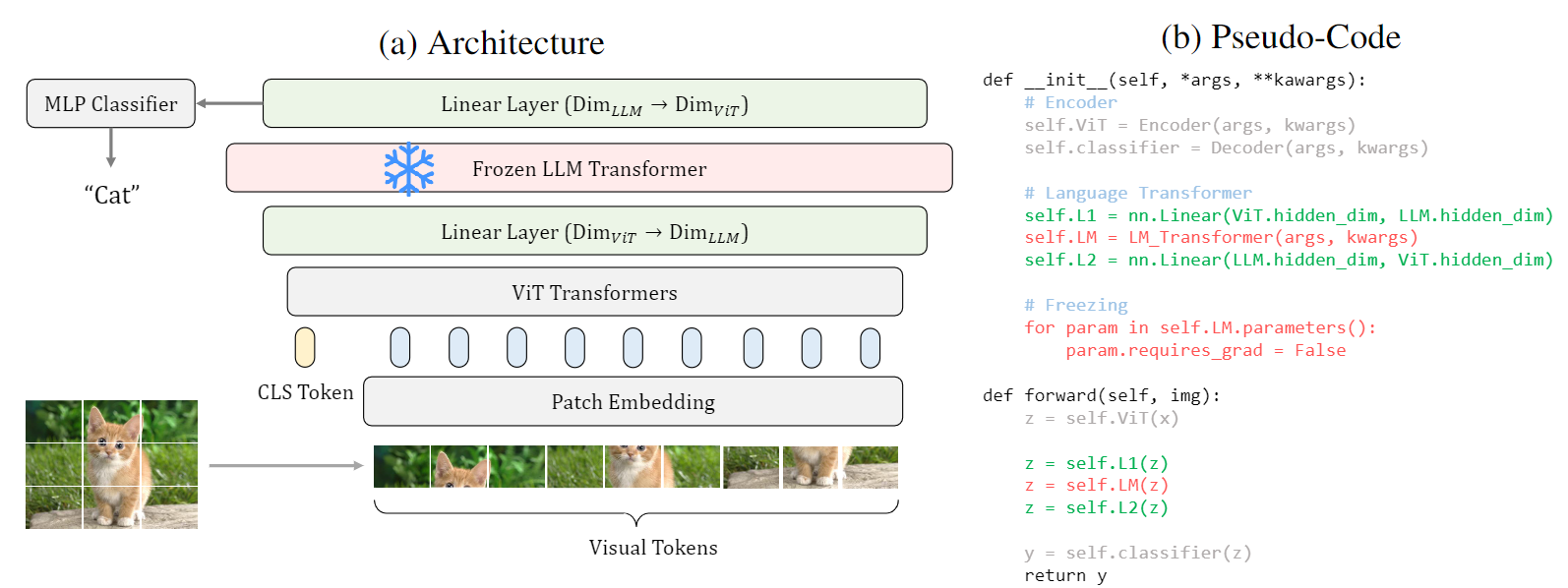
Frozen Transformers in Language Models Are Effective Visual Encoder Layers
This paper reveals that large language models (LLMs), despite being trained solely on textual data, are surprisingly strong encoders for purely visual tasks in the absence of language. Even more intriguingly, this can be achieved by a simple yet previously overlooked strategy -- employing a frozen transformer block from pre-trained LLMs as a constituent encoder layer to directly process visual tokens. Our work pushes the boundaries of leveraging LLMs for computer vision tasks, significantly departing from conventional practices that typically necessitate a multi-modal vision-language setup with associated language prompts, inputs, or outputs. We demonstrate that our approach consistently enhances performance across a diverse range of tasks, encompassing pure 2D and 3D visual recognition tasks (e.g., image and point cloud classification), temporal modeling tasks (e.g., action recognition), non-semantic tasks (e.g., motion forecasting), and multi-modal tasks (e.g., 2D/3D visual question answering and image-text retrieval). Such improvements are a general phenomenon, applicable to various types of LLMs (e.g., LLaMA and OPT) and different LLM transformer blocks. We additionally propose the information filtering hypothesis to explain the effectiveness of pre-trained LLMs in visual encoding -- the pre-trained LLM transformer blocks discern informative visual tokens and further amplify their effect. This hypothesis is empirically supported by the observation that the feature activation, after training with LLM transformer blocks, exhibits a stronger focus on relevant regions. We hope that our work inspires new perspectives on utilizing LLMs and deepening our understanding of their underlying mechanisms. Code is available at https://github.com/ziqipang/LM4VisualEncoding.
PDF Abstract



 ImageNet
ImageNet
 ShapeNet
ShapeNet
 ImageNet-C
ImageNet-C
 ImageNet-R
ImageNet-R
 ImageNet-A
ImageNet-A
 SQA3D
SQA3D

