From Chaos Comes Order: Ordering Event Representations for Object Recognition and Detection
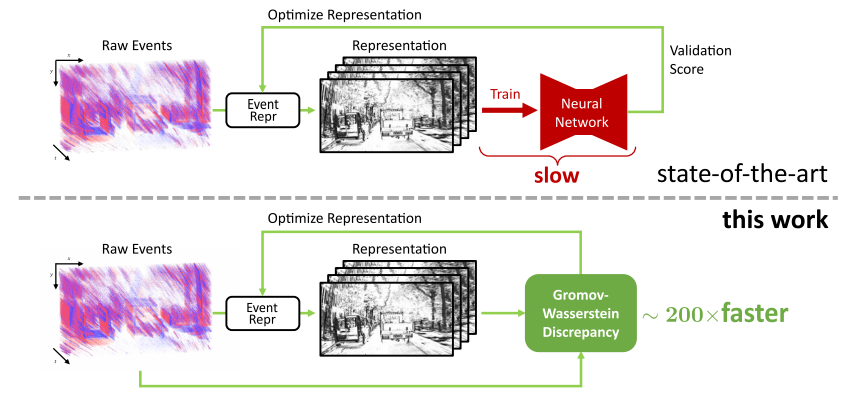
Today, state-of-the-art deep neural networks that process events first convert them into dense, grid-like input representations before using an off-the-shelf network. However, selecting the appropriate representation for the task traditionally requires training a neural network for each representation and selecting the best one based on the validation score, which is very time-consuming. This work eliminates this bottleneck by selecting representations based on the Gromov-Wasserstein Discrepancy (GWD) between raw events and their representation. It is about 200 times faster to compute than training a neural network and preserves the task performance ranking of event representations across multiple representations, network backbones, datasets, and tasks. Thus finding representations with high task scores is equivalent to finding representations with a low GWD. We use this insight to, for the first time, perform a hyperparameter search on a large family of event representations, revealing new and powerful representations that exceed the state-of-the-art. Our optimized representations outperform existing representations by 1.7 mAP on the 1 Mpx dataset and 0.3 mAP on the Gen1 dataset, two established object detection benchmarks, and reach a 3.8% higher classification score on the mini N-ImageNet benchmark. Moreover, we outperform state-of-the-art by 2.1 mAP on Gen1 and state-of-the-art feed-forward methods by 6.0 mAP on the 1 Mpx datasets. This work opens a new unexplored field of explicit representation optimization for event-based learning.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract





 N-ImageNet
N-ImageNet

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Object Detection | GEN1 Detection | ERGO-12 | mAP | 50.4 | # 1 |
