Found in the Middle: Permutation Self-Consistency Improves Listwise Ranking in Large Language Models
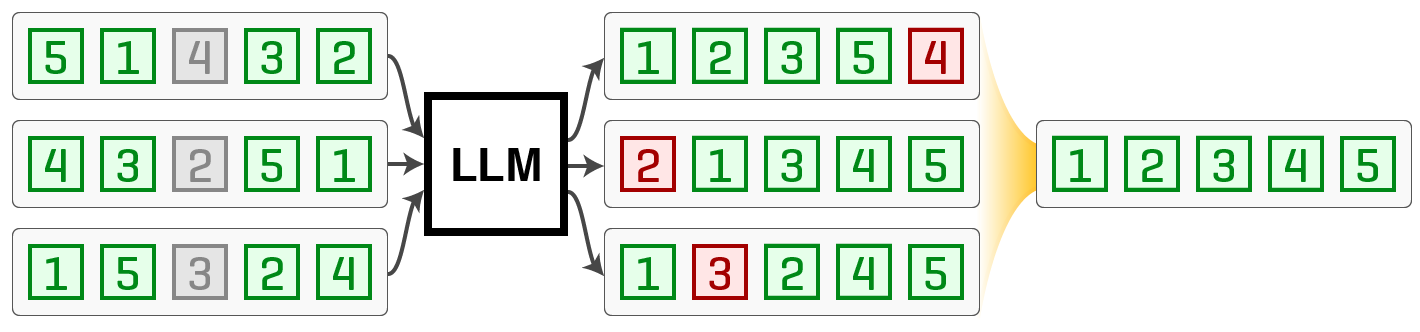
Large language models (LLMs) exhibit positional bias in how they use context, which especially complicates listwise ranking. To address this, we propose permutation self-consistency, a form of self-consistency over ranking list outputs of black-box LLMs. Our key idea is to marginalize out different list orders in the prompt to produce an order-independent ranking with less positional bias. First, given some input prompt, we repeatedly shuffle the list in the prompt and pass it through the LLM while holding the instructions the same. Next, we aggregate the resulting sample of rankings by computing the central ranking closest in distance to all of them, marginalizing out prompt order biases in the process. Theoretically, we prove the robustness of our method, showing convergence to the true ranking in the presence of random perturbations. Empirically, on five list-ranking datasets in sorting and passage reranking, our approach improves scores from conventional inference by up to 7-18% for GPT-3.5 and 8-16% for LLaMA v2 (70B), surpassing the previous state of the art in passage reranking. Our code is at https://github.com/castorini/perm-sc.
PDF Abstract Spaces
Spaces
 GSM8K
GSM8K
