EMIFF: Enhanced Multi-scale Image Feature Fusion for Vehicle-Infrastructure Cooperative 3D Object Detection
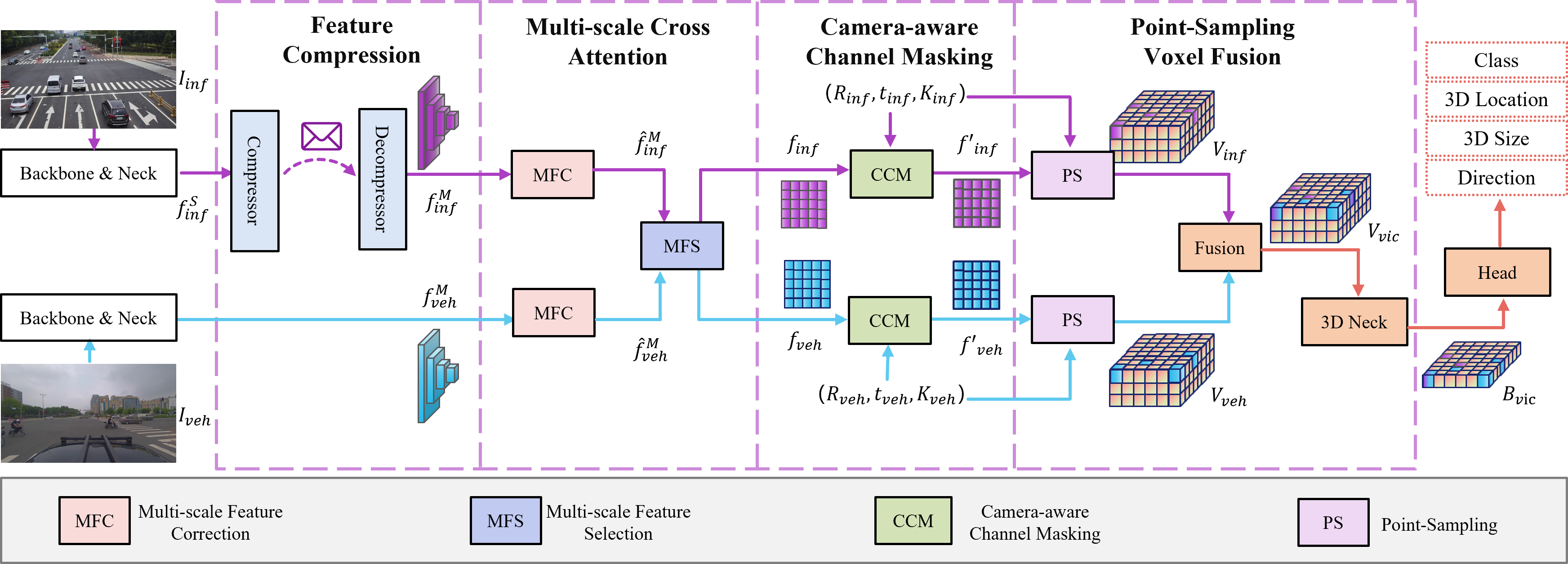
In autonomous driving, cooperative perception makes use of multi-view cameras from both vehicles and infrastructure, providing a global vantage point with rich semantic context of road conditions beyond a single vehicle viewpoint. Currently, two major challenges persist in vehicle-infrastructure cooperative 3D (VIC3D) object detection: $1)$ inherent pose errors when fusing multi-view images, caused by time asynchrony across cameras; $2)$ information loss in transmission process resulted from limited communication bandwidth. To address these issues, we propose a novel camera-based 3D detection framework for VIC3D task, Enhanced Multi-scale Image Feature Fusion (EMIFF). To fully exploit holistic perspectives from both vehicles and infrastructure, we propose Multi-scale Cross Attention (MCA) and Camera-aware Channel Masking (CCM) modules to enhance infrastructure and vehicle features at scale, spatial, and channel levels to correct the pose error introduced by camera asynchrony. We also introduce a Feature Compression (FC) module with channel and spatial compression blocks for transmission efficiency. Experiments show that EMIFF achieves SOTA on DAIR-V2X-C datasets, significantly outperforming previous early-fusion and late-fusion methods with comparable transmission costs.
PDF Abstract




 OPV2V
OPV2V
