Depth-based 6DoF Object Pose Estimation using Swin Transformer
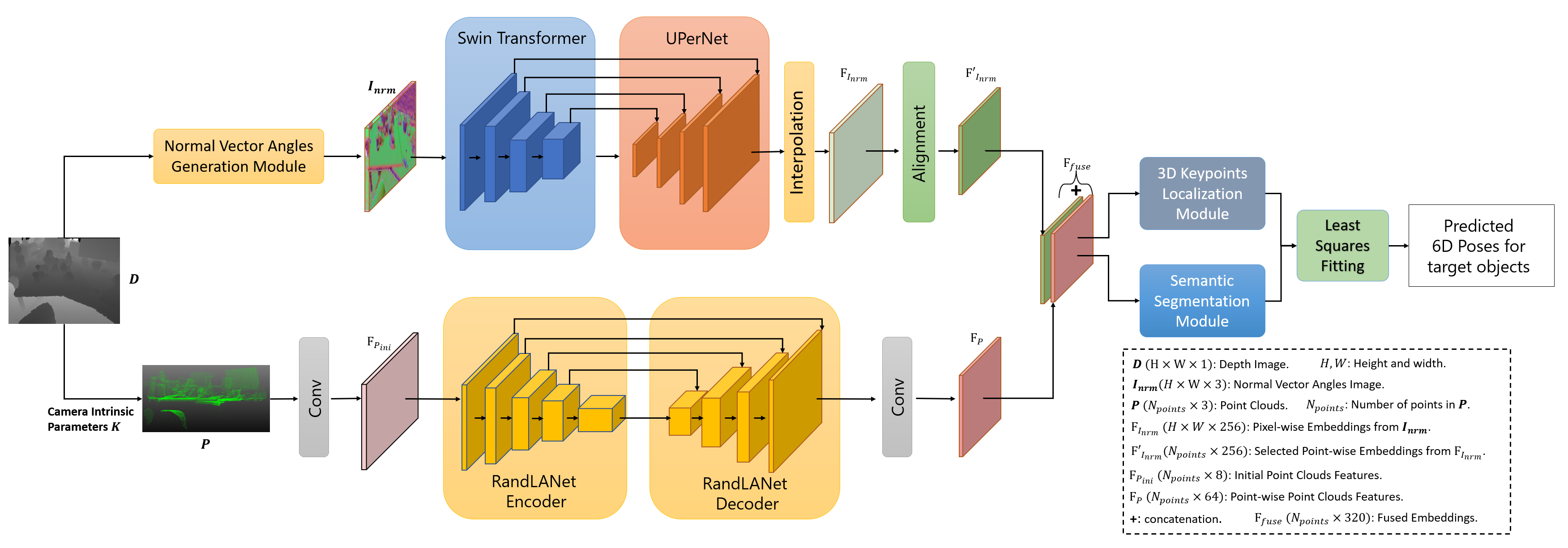
Accurately estimating the 6D pose of objects is crucial for many applications, such as robotic grasping, autonomous driving, and augmented reality. However, this task becomes more challenging in poor lighting conditions or when dealing with textureless objects. To address this issue, depth images are becoming an increasingly popular choice due to their invariance to a scene's appearance and the implicit incorporation of essential geometric characteristics. However, fully leveraging depth information to improve the performance of pose estimation remains a difficult and under-investigated problem. To tackle this challenge, we propose a novel framework called SwinDePose, that uses only geometric information from depth images to achieve accurate 6D pose estimation. SwinDePose first calculates the angles between each normal vector defined in a depth image and the three coordinate axes in the camera coordinate system. The resulting angles are then formed into an image, which is encoded using Swin Transformer. Additionally, we apply RandLA-Net to learn the representations from point clouds. The resulting image and point clouds embeddings are concatenated and fed into a semantic segmentation module and a 3D keypoints localization module. Finally, we estimate 6D poses using a least-square fitting approach based on the target object's predicted semantic mask and 3D keypoints. In experiments on the LineMod and Occlusion LineMod datasets, SwinDePose outperforms existing state-of-the-art methods for 6D object pose estimation using depth images. This demonstrates the effectiveness of our approach and highlights its potential for improving performance in real-world scenarios. Our code is at https://github.com/zhujunli1993/SwinDePose.
PDF Abstract






