Curricular Subgoals for Inverse Reinforcement Learning
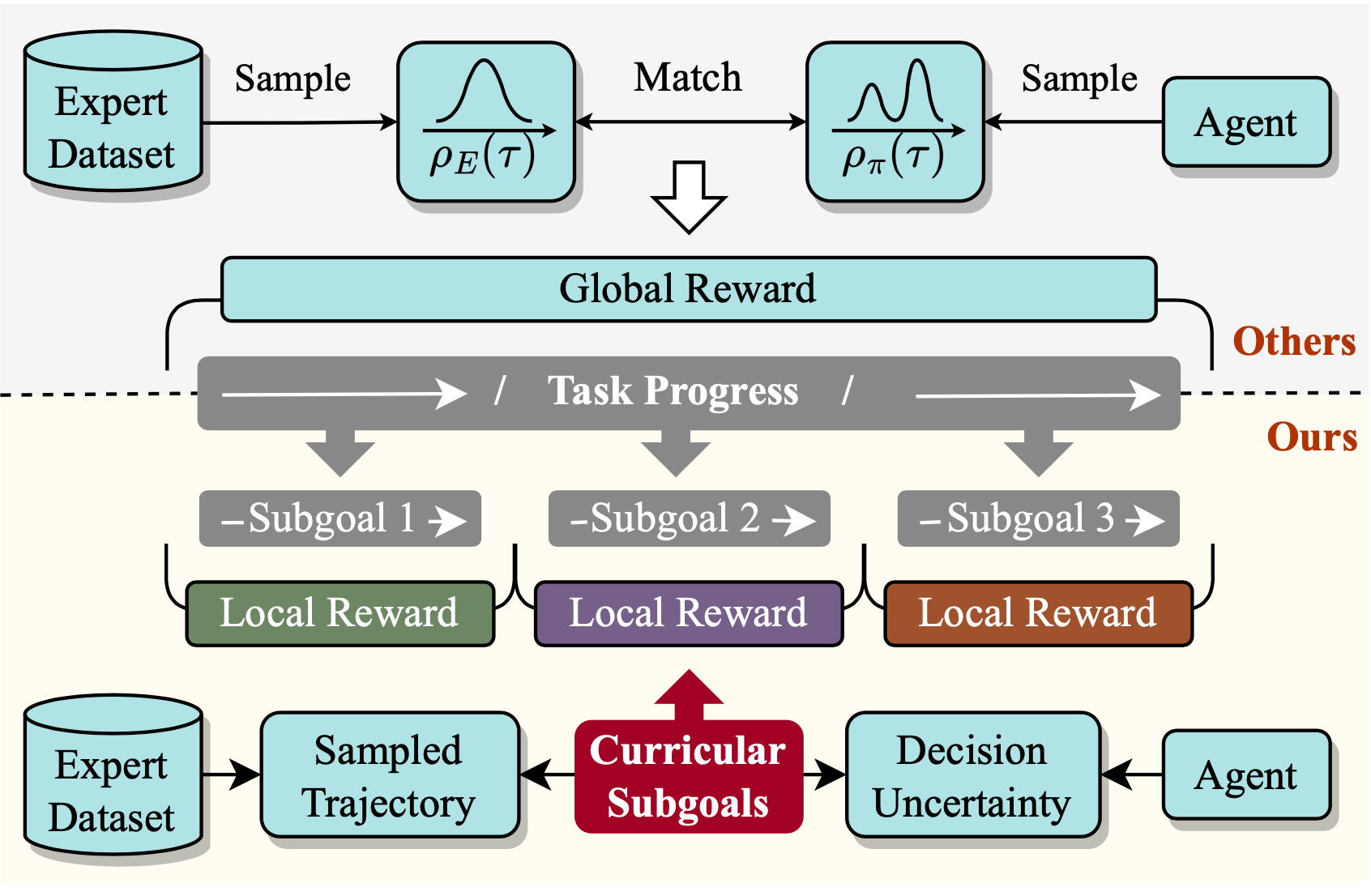
Inverse Reinforcement Learning (IRL) aims to reconstruct the reward function from expert demonstrations to facilitate policy learning, and has demonstrated its remarkable success in imitation learning. To promote expert-like behavior, existing IRL methods mainly focus on learning global reward functions to minimize the trajectory difference between the imitator and the expert. However, these global designs are still limited by the redundant noise and error propagation problems, leading to the unsuitable reward assignment and thus downgrading the agent capability in complex multi-stage tasks. In this paper, we propose a novel Curricular Subgoal-based Inverse Reinforcement Learning (CSIRL) framework, that explicitly disentangles one task with several local subgoals to guide agent imitation. Specifically, CSIRL firstly introduces decision uncertainty of the trained agent over expert trajectories to dynamically select subgoals, which directly determines the exploration boundary of different task stages. To further acquire local reward functions for each stage, we customize a meta-imitation objective based on these curricular subgoals to train an intrinsic reward generator. Experiments on the D4RL and autonomous driving benchmarks demonstrate that the proposed methods yields results superior to the state-of-the-art counterparts, as well as better interpretability. Our code is available at https://github.com/Plankson/CSIRL.
PDF Abstract


 D4RL
D4RL
