Cross-modal Attention Congruence Regularization for Vision-Language Relation Alignment
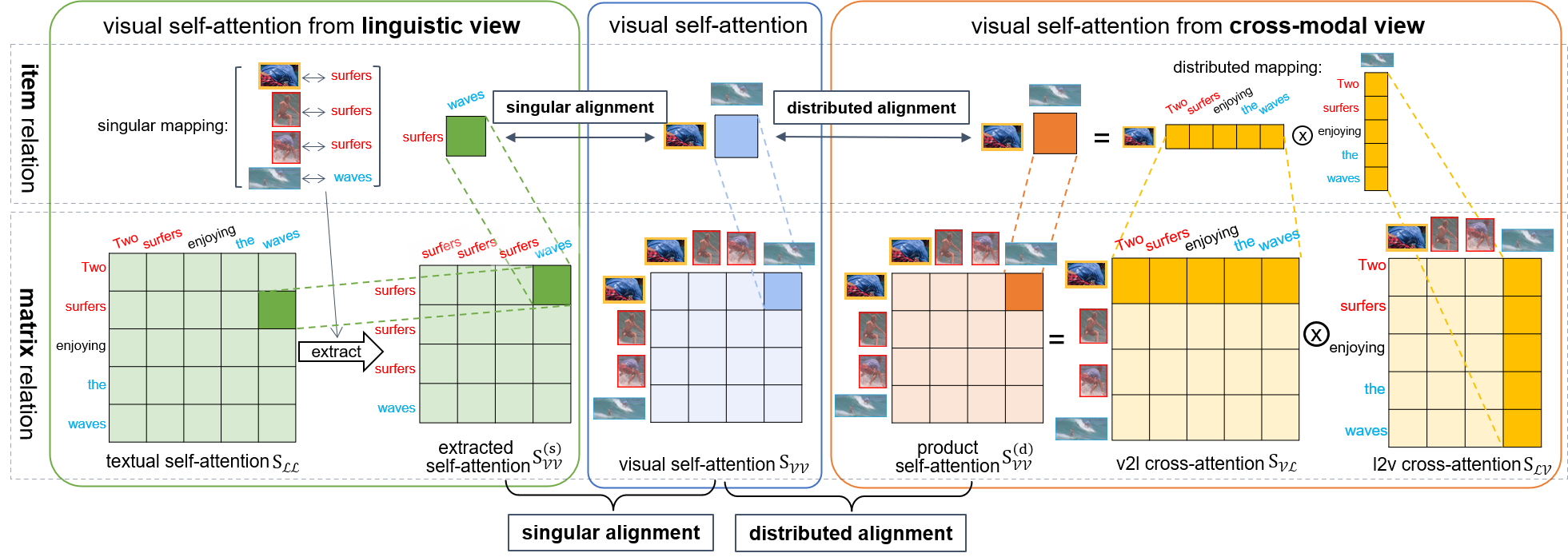
Despite recent progress towards scaling up multimodal vision-language models, these models are still known to struggle on compositional generalization benchmarks such as Winoground. We find that a critical component lacking from current vision-language models is relation-level alignment: the ability to match directional semantic relations in text (e.g., "mug in grass") with spatial relationships in the image (e.g., the position of the mug relative to the grass). To tackle this problem, we show that relation alignment can be enforced by encouraging the directed language attention from 'mug' to 'grass' (capturing the semantic relation 'in') to match the directed visual attention from the mug to the grass. Tokens and their corresponding objects are softly identified using the cross-modal attention. We prove that this notion of soft relation alignment is equivalent to enforcing congruence between vision and language attention matrices under a 'change of basis' provided by the cross-modal attention matrix. Intuitively, our approach projects visual attention into the language attention space to calculate its divergence from the actual language attention, and vice versa. We apply our Cross-modal Attention Congruence Regularization (CACR) loss to UNITER and improve on the state-of-the-art approach to Winoground.
PDF Abstract

 Flickr30k
Flickr30k
