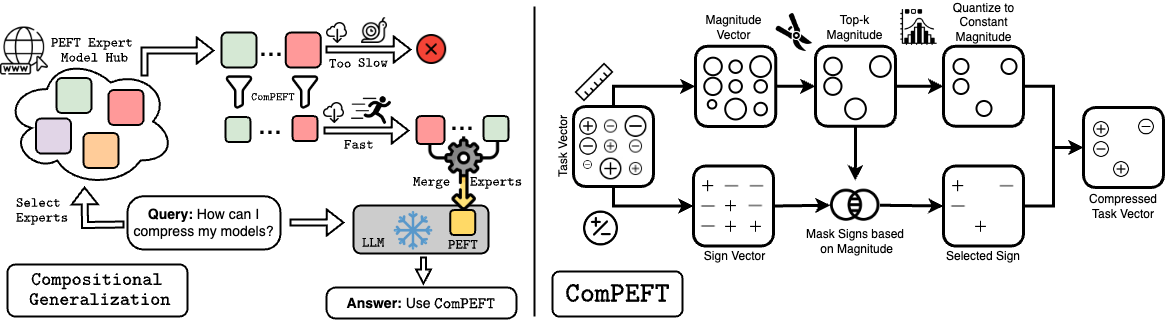
ComPEFT: Compression for Communicating Parameter Efficient Updates via Sparsification and Quantization
Parameter-efficient fine-tuning (PEFT) techniques make it possible to efficiently adapt a language model to create "expert" models that specialize to new tasks or domains. Recent techniques in model merging and compositional generalization leverage these expert models by dynamically composing modules to improve zero/few-shot generalization. Despite the efficiency of PEFT methods, the size of expert models can make it onerous to retrieve expert models per query over high-latency networks like the Internet or serve multiple experts on a single GPU. To address these issues, we present ComPEFT, a novel method for compressing fine-tuning residuals (task vectors) of PEFT based models. ComPEFT employs sparsification and ternary quantization to reduce the size of the PEFT module without performing any additional retraining while preserving or enhancing model performance. In extensive evaluation across T5, T0, and LLaMA-based models with 200M - 65B parameters, ComPEFT achieves compression ratios of 8x - 50x. In particular, we show that ComPEFT improves with scale - stronger models exhibit higher compressibility and better performance. For example, we show that ComPEFT applied to LLaMA outperforms QLoRA by 4.16% on MMLU with a storage size reduction of up to 26x. In addition, we show that the compressed experts produced by ComPEFT maintain few-shot compositional generalization capabilities, facilitate efficient communication and computation, and exhibit enhanced performance when merged. Lastly, we provide an analysis of different method components, compare it with other PEFT methods, and test ComPEFT's efficacy for compressing the residual of full-finetuning. Our code is available at https://github.com/prateeky2806/compeft.
PDF Abstract


 GLUE
GLUE
 MMLU
MMLU
