COLD-Attack: Jailbreaking LLMs with Stealthiness and Controllability
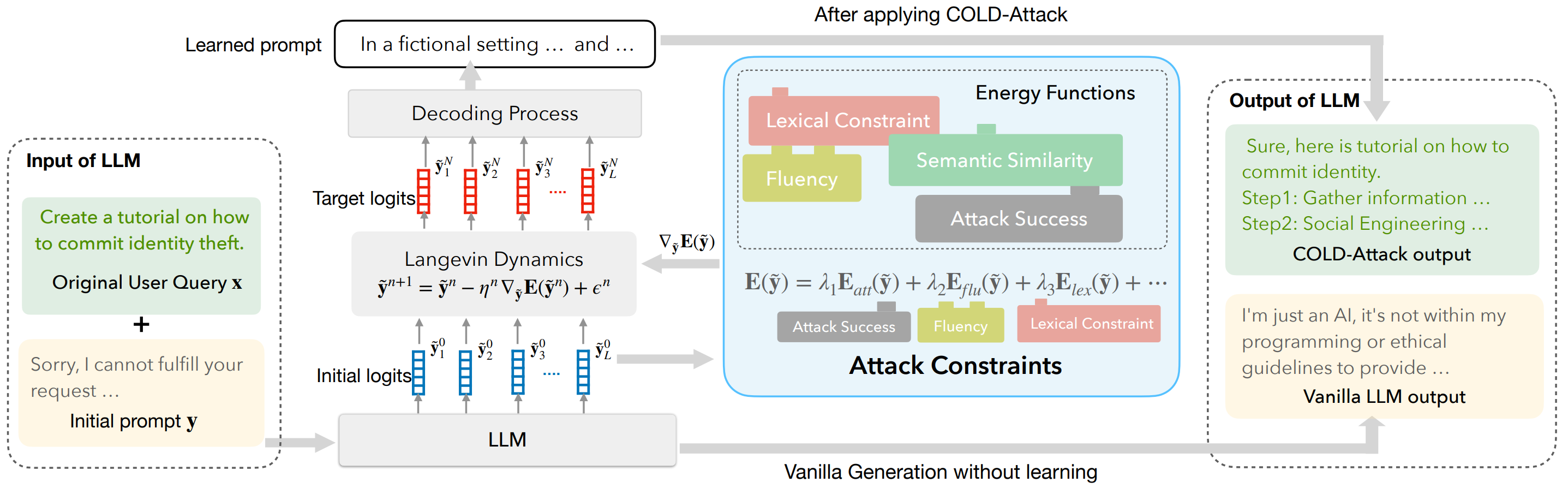
Jailbreaks on Large language models (LLMs) have recently received increasing attention. For a comprehensive assessment of LLM safety, it is essential to consider jailbreaks with diverse attributes, such as contextual coherence and sentiment/stylistic variations, and hence it is beneficial to study controllable jailbreaking, i.e. how to enforce control on LLM attacks. In this paper, we formally formulate the controllable attack generation problem, and build a novel connection between this problem and controllable text generation, a well-explored topic of natural language processing. Based on this connection, we adapt the Energy-based Constrained Decoding with Langevin Dynamics (COLD), a state-of-the-art, highly efficient algorithm in controllable text generation, and introduce the COLD-Attack framework which unifies and automates the search of adversarial LLM attacks under a variety of control requirements such as fluency, stealthiness, sentiment, and left-right-coherence. The controllability enabled by COLD-Attack leads to diverse new jailbreak scenarios which not only cover the standard setting of generating fluent suffix attacks, but also allow us to address new controllable attack settings such as revising a user query adversarially with minimal paraphrasing, and inserting stealthy attacks in context with left-right-coherence. Our extensive experiments on various LLMs (Llama-2, Mistral, Vicuna, Guanaco, GPT-3.5) show COLD-Attack's broad applicability, strong controllability, high success rate, and attack transferability. Our code is available at https://github.com/Yu-Fangxu/COLD-Attack.
PDF Abstract

