CoBEVT: Cooperative Bird's Eye View Semantic Segmentation with Sparse Transformers
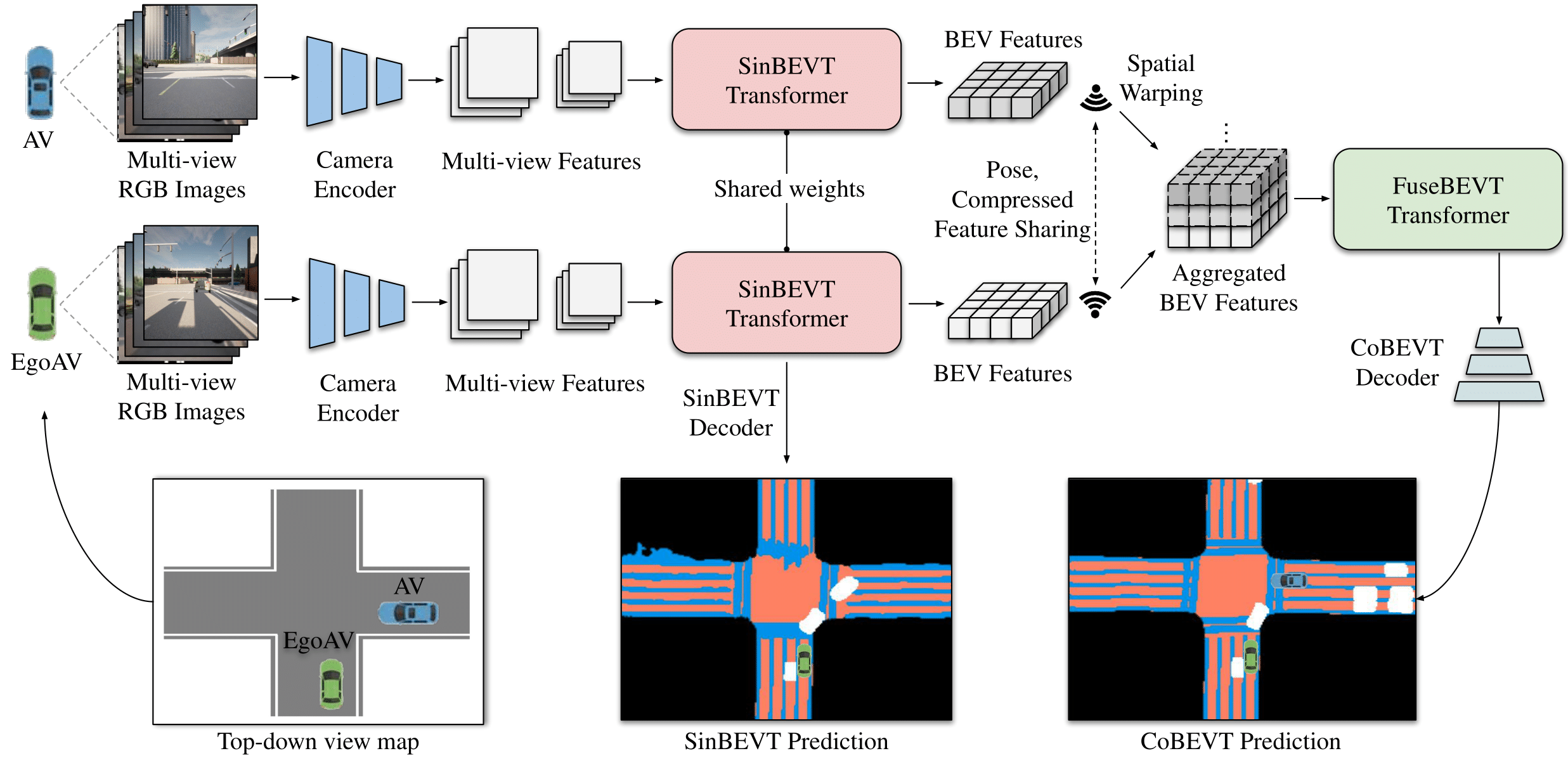
Bird's eye view (BEV) semantic segmentation plays a crucial role in spatial sensing for autonomous driving. Although recent literature has made significant progress on BEV map understanding, they are all based on single-agent camera-based systems. These solutions sometimes have difficulty handling occlusions or detecting distant objects in complex traffic scenes. Vehicle-to-Vehicle (V2V) communication technologies have enabled autonomous vehicles to share sensing information, dramatically improving the perception performance and range compared to single-agent systems. In this paper, we propose CoBEVT, the first generic multi-agent multi-camera perception framework that can cooperatively generate BEV map predictions. To efficiently fuse camera features from multi-view and multi-agent data in an underlying Transformer architecture, we design a fused axial attention module (FAX), which captures sparsely local and global spatial interactions across views and agents. The extensive experiments on the V2V perception dataset, OPV2V, demonstrate that CoBEVT achieves state-of-the-art performance for cooperative BEV semantic segmentation. Moreover, CoBEVT is shown to be generalizable to other tasks, including 1) BEV segmentation with single-agent multi-camera and 2) 3D object detection with multi-agent LiDAR systems, achieving state-of-the-art performance with real-time inference speed. The code is available at https://github.com/DerrickXuNu/CoBEVT.
PDF Abstract






 nuScenes
nuScenes
 OPV2V
OPV2V
