CMT: Convolutional Neural Networks Meet Vision Transformers
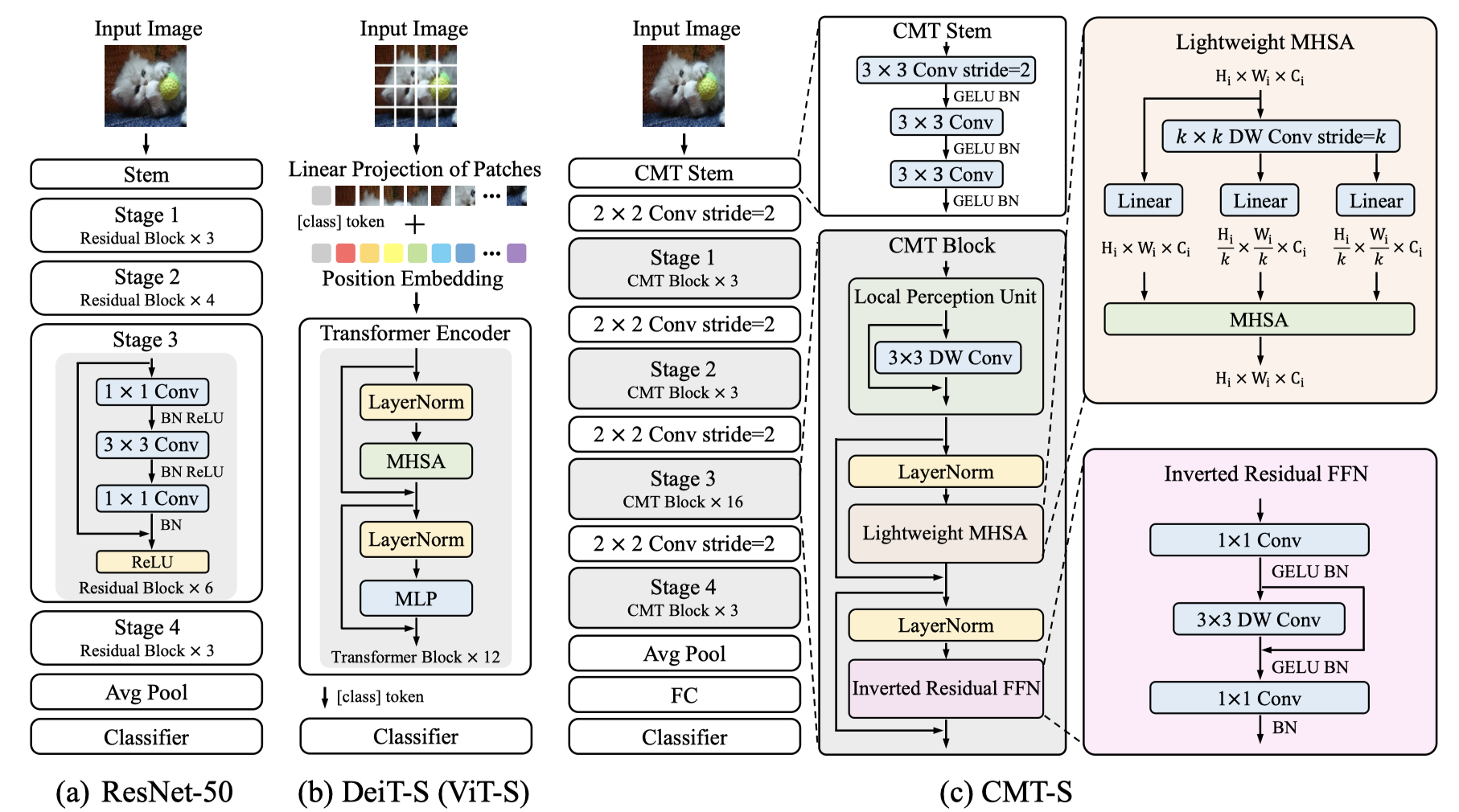
Vision transformers have been successfully applied to image recognition tasks due to their ability to capture long-range dependencies within an image. However, there are still gaps in both performance and computational cost between transformers and existing convolutional neural networks (CNNs). In this paper, we aim to address this issue and develop a network that can outperform not only the canonical transformers, but also the high-performance convolutional models. We propose a new transformer based hybrid network by taking advantage of transformers to capture long-range dependencies, and of CNNs to model local features. Furthermore, we scale it to obtain a family of models, called CMTs, obtaining much better accuracy and efficiency than previous convolution and transformer based models. In particular, our CMT-S achieves 83.5% top-1 accuracy on ImageNet, while being 14x and 2x smaller on FLOPs than the existing DeiT and EfficientNet, respectively. The proposed CMT-S also generalizes well on CIFAR10 (99.2%), CIFAR100 (91.7%), Flowers (98.7%), and other challenging vision datasets such as COCO (44.3% mAP), with considerably less computational cost.
PDF Abstract CVPR 2022 PDF CVPR 2022 Abstract


 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 MS COCO
MS COCO
 CIFAR-100
CIFAR-100
 Oxford 102 Flower
Oxford 102 Flower
