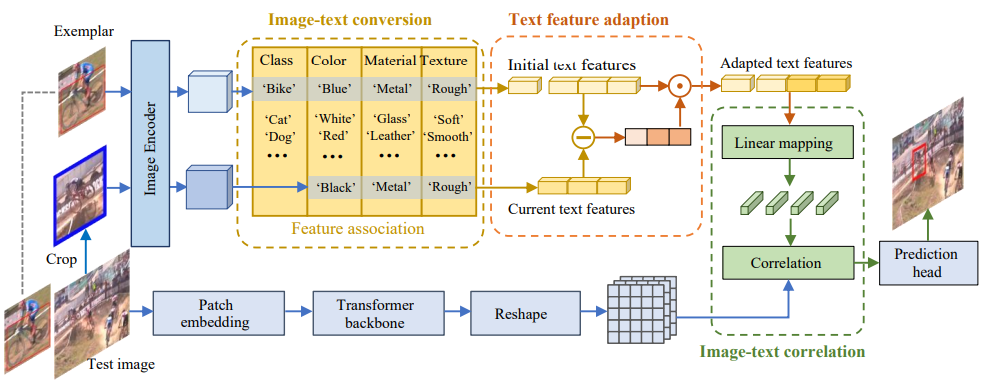
CiteTracker: Correlating Image and Text for Visual Tracking
Existing visual tracking methods typically take an image patch as the reference of the target to perform tracking. However, a single image patch cannot provide a complete and precise concept of the target object as images are limited in their ability to abstract and can be ambiguous, which makes it difficult to track targets with drastic variations. In this paper, we propose the CiteTracker to enhance target modeling and inference in visual tracking by connecting images and text. Specifically, we develop a text generation module to convert the target image patch into a descriptive text containing its class and attribute information, providing a comprehensive reference point for the target. In addition, a dynamic description module is designed to adapt to target variations for more effective target representation. We then associate the target description and the search image using an attention-based correlation module to generate the correlated features for target state reference. Extensive experiments on five diverse datasets are conducted to evaluate the proposed algorithm and the favorable performance against the state-of-the-art methods demonstrates the effectiveness of the proposed tracking method.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract


 MS COCO
MS COCO
 LaSOT
LaSOT
 GOT-10k
GOT-10k
 TrackingNet
TrackingNet
 TNL2K
TNL2K
