Bridging Vision and Language Encoders: Parameter-Efficient Tuning for Referring Image Segmentation
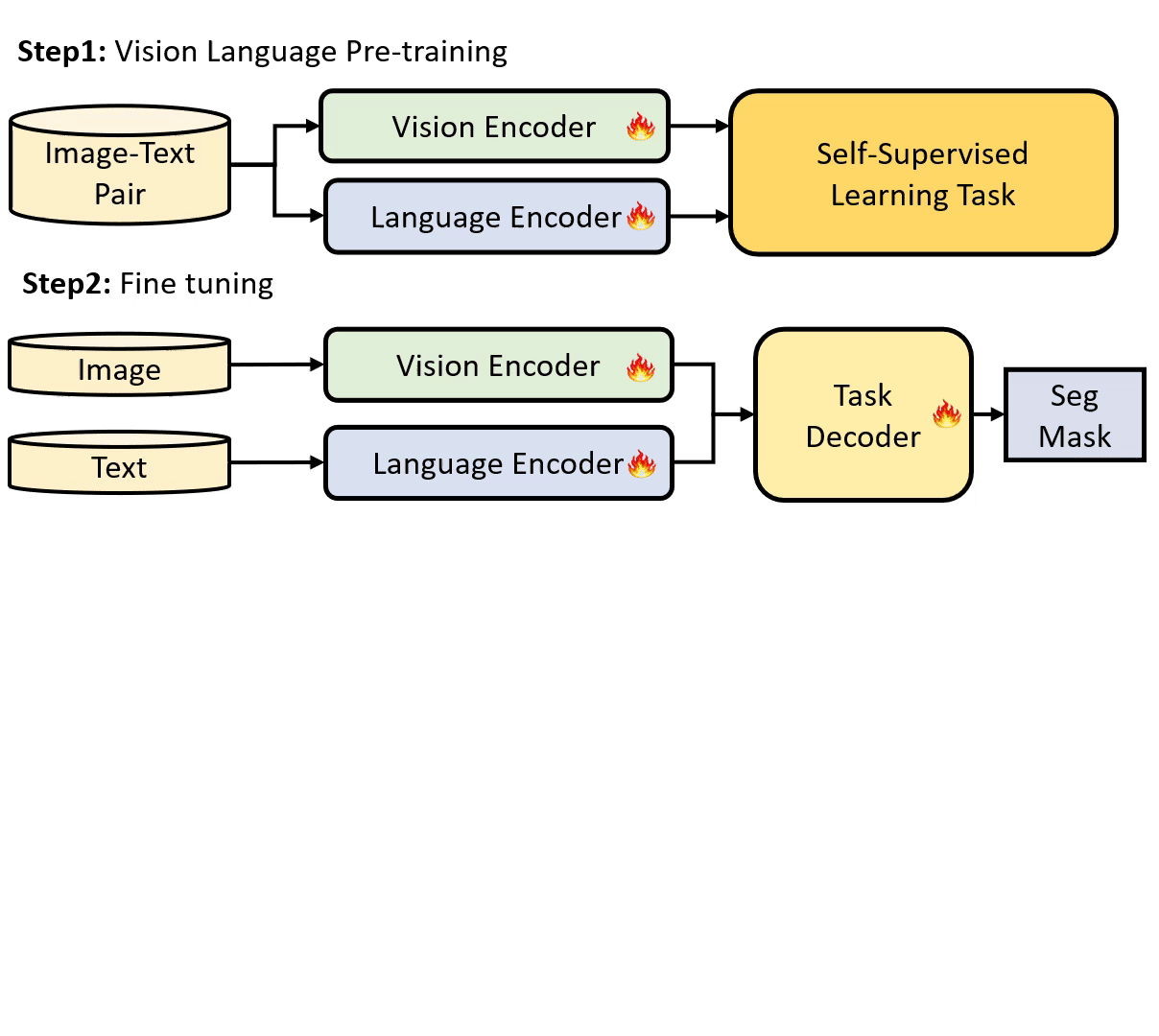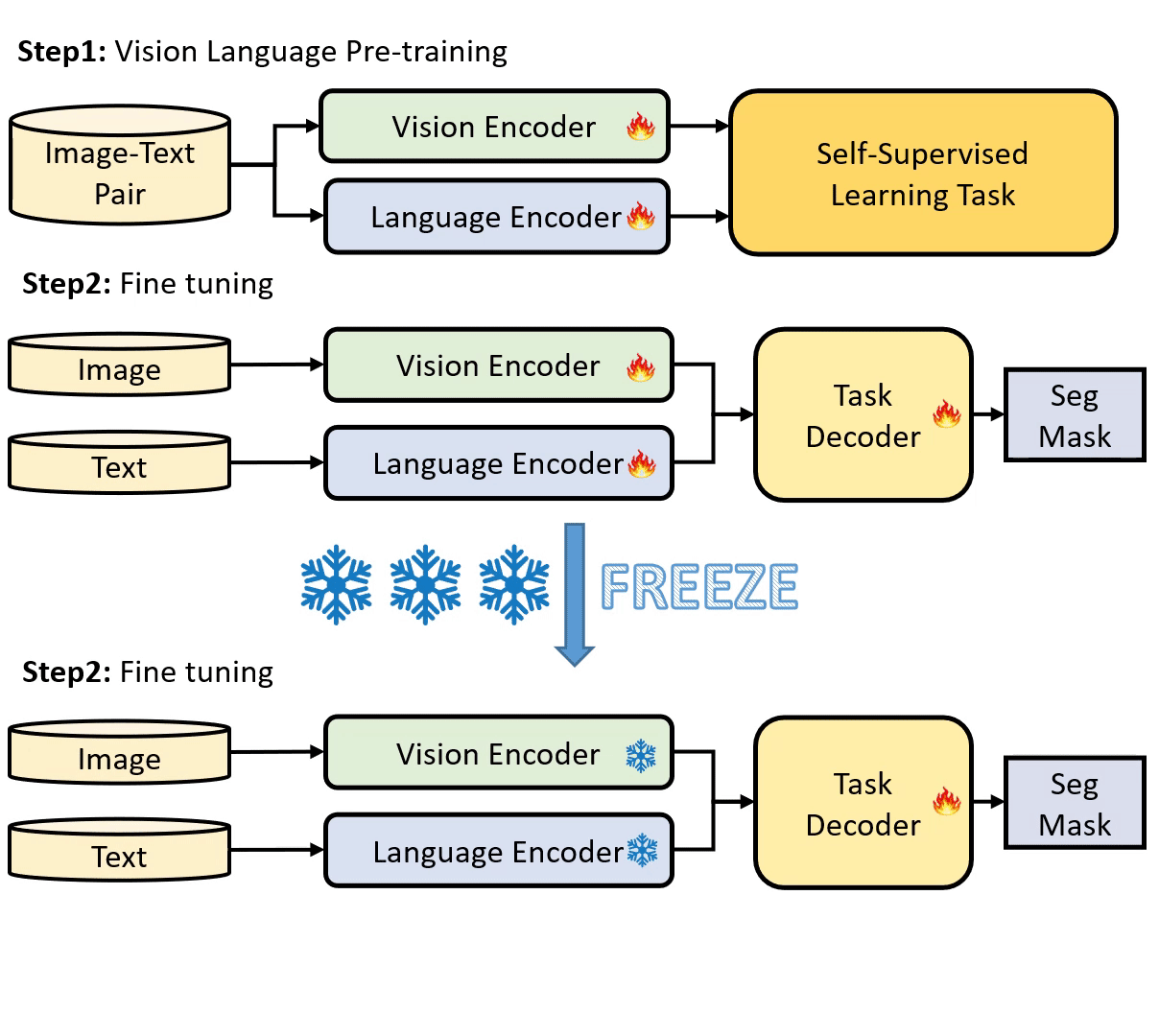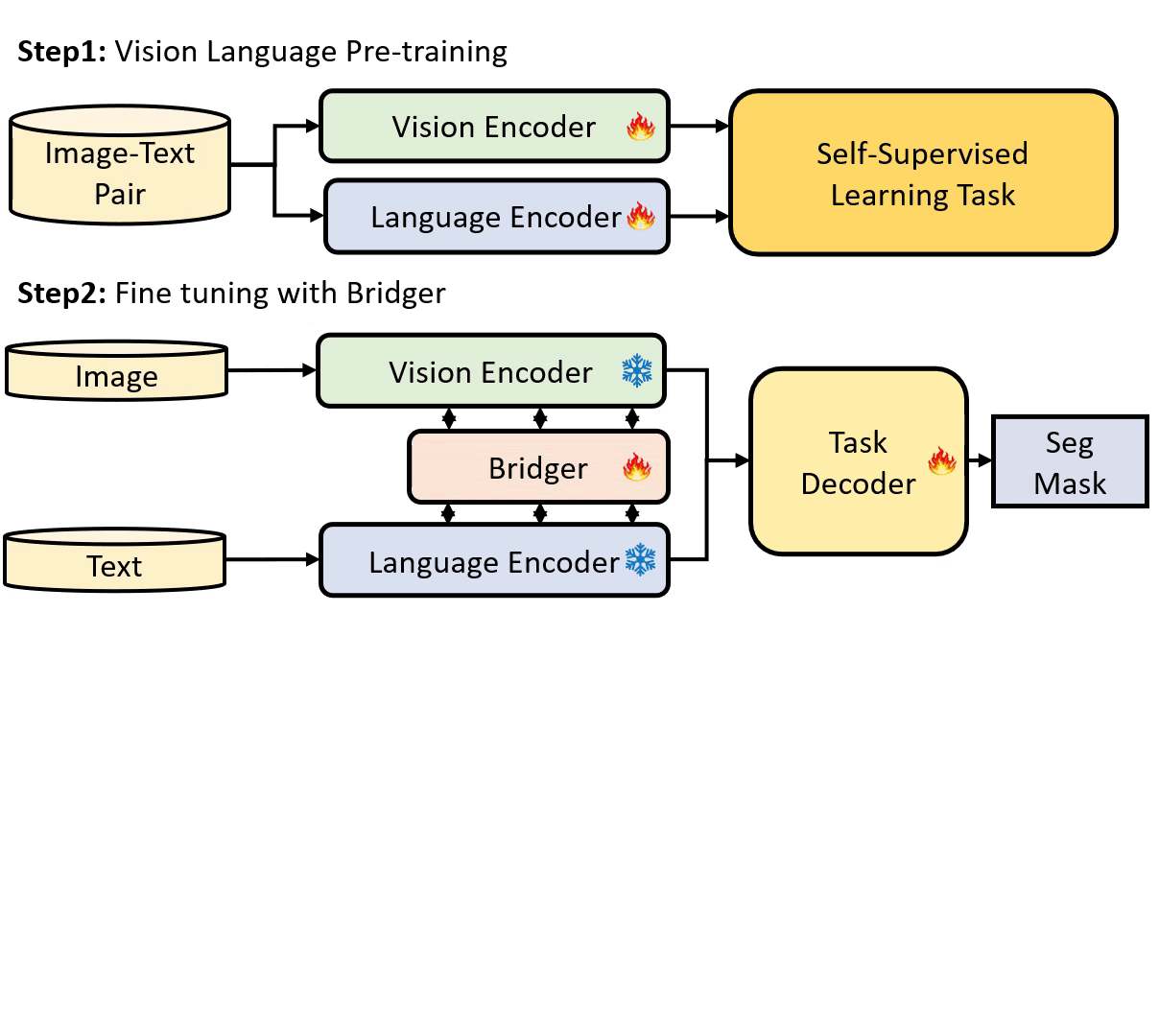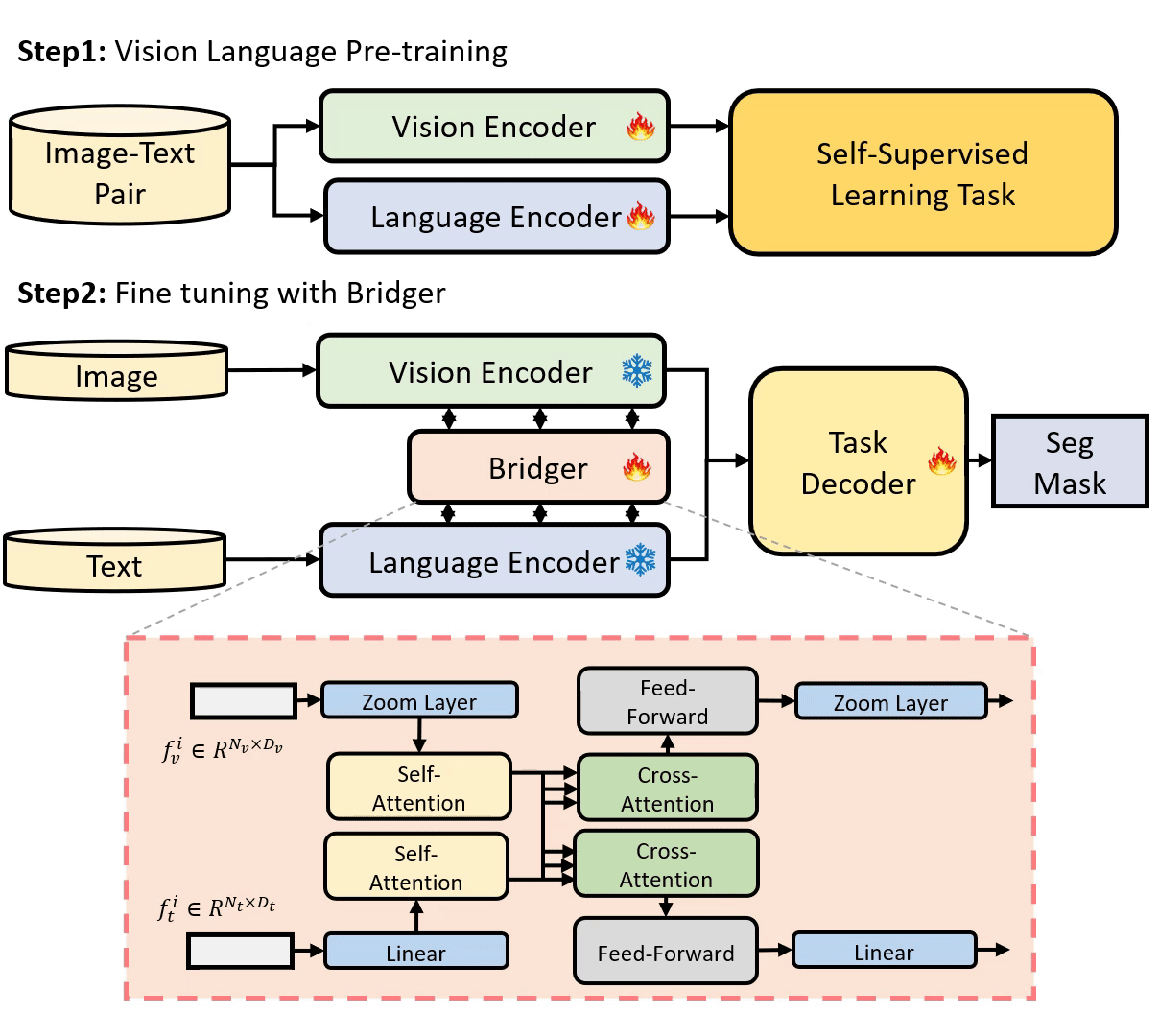
Parameter Efficient Tuning (PET) has gained attention for reducing the number of parameters while maintaining performance and providing better hardware resource savings, but few studies investigate dense prediction tasks and interaction between modalities. In this paper, we do an investigation of efficient tuning problems on referring image segmentation. We propose a novel adapter called Bridger to facilitate cross-modal information exchange and inject task-specific information into the pre-trained model. We also design a lightweight decoder for image segmentation. Our approach achieves comparable or superior performance with only 1.61\% to 3.38\% backbone parameter updates, evaluated on challenging benchmarks. The code is available at \url{https://github.com/kkakkkka/ETRIS}.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract



 MS COCO
MS COCO
 RefCOCO
RefCOCO

