Boosting Segment Anything Model Towards Open-Vocabulary Learning
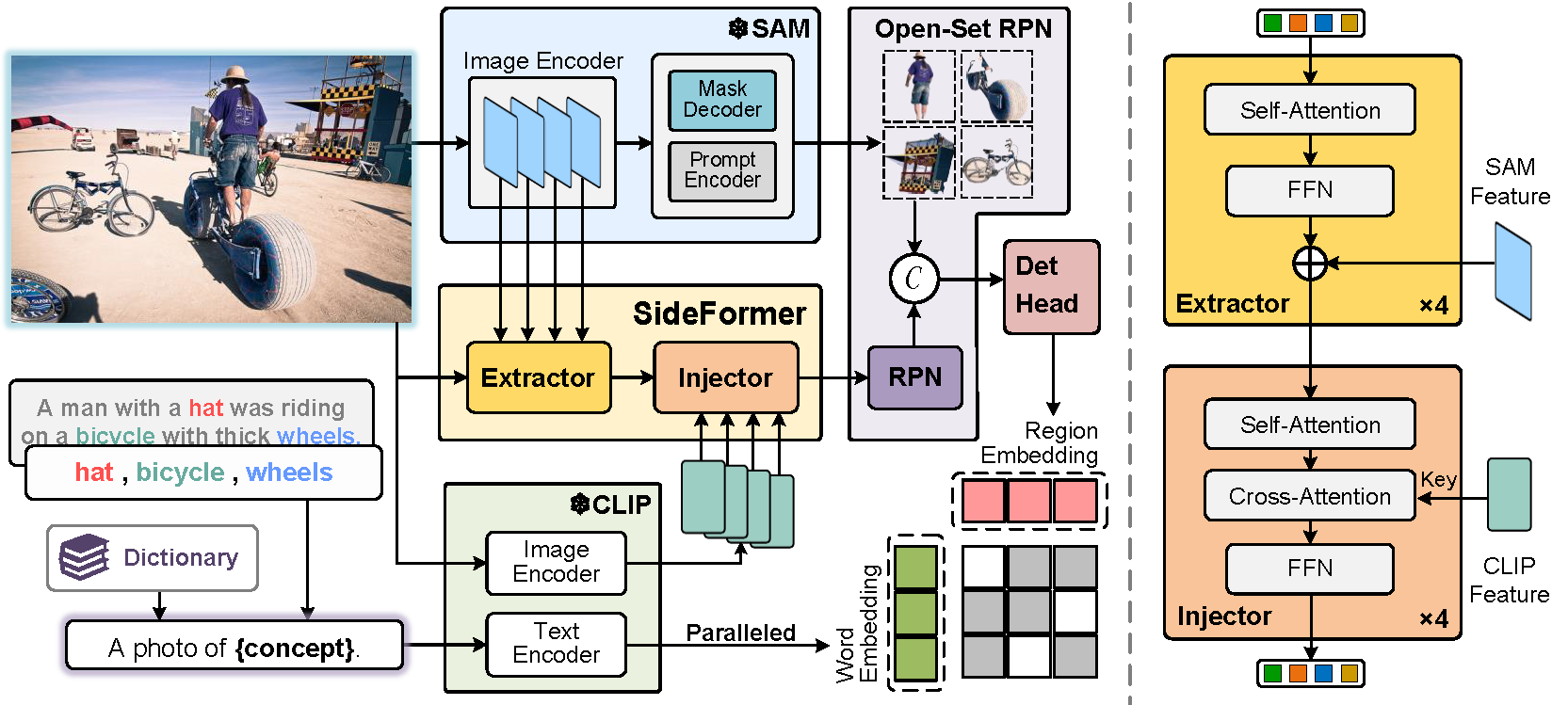
The recent Segment Anything Model (SAM) has emerged as a new paradigmatic vision foundation model, showcasing potent zero-shot generalization and flexible prompting. Despite SAM finding applications and adaptations in various domains, its primary limitation lies in the inability to grasp object semantics. In this paper, we present Sambor to seamlessly integrate SAM with the open-vocabulary object detector in an end-to-end framework. While retaining all the remarkable capabilities inherent to SAM, we enhance it with the capacity to detect arbitrary objects based on human inputs like category names or reference expressions. To accomplish this, we introduce a novel SideFormer module that extracts SAM features to facilitate zero-shot object localization and inject comprehensive semantic information for open-vocabulary recognition. In addition, we devise an open-set region proposal network (Open-set RPN), enabling the detector to acquire the open-set proposals generated by SAM. Sambor demonstrates superior zero-shot performance across benchmarks, including COCO and LVIS, proving highly competitive against previous SoTA methods. We aspire for this work to serve as a meaningful endeavor in endowing SAM to recognize diverse object categories and advancing open-vocabulary learning with the support of vision foundation models.
PDF Abstract
 MS COCO
MS COCO
 LVIS
LVIS
