Benchmarking Retrieval-Augmented Generation for Medicine
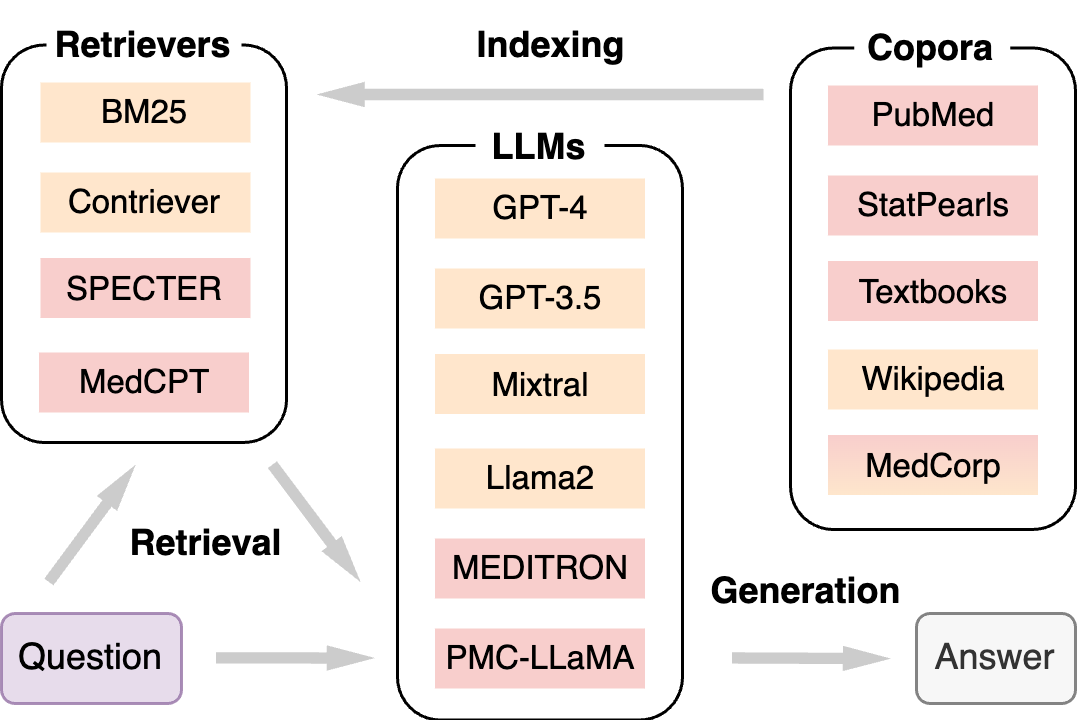
While large language models (LLMs) have achieved state-of-the-art performance on a wide range of medical question answering (QA) tasks, they still face challenges with hallucinations and outdated knowledge. Retrieval-augmented generation (RAG) is a promising solution and has been widely adopted. However, a RAG system can involve multiple flexible components, and there is a lack of best practices regarding the optimal RAG setting for various medical purposes. To systematically evaluate such systems, we propose the Medical Information Retrieval-Augmented Generation Evaluation (MIRAGE), a first-of-its-kind benchmark including 7,663 questions from five medical QA datasets. Using MIRAGE, we conducted large-scale experiments with over 1.8 trillion prompt tokens on 41 combinations of different corpora, retrievers, and backbone LLMs through the MedRAG toolkit introduced in this work. Overall, MedRAG improves the accuracy of six different LLMs by up to 18% over chain-of-thought prompting, elevating the performance of GPT-3.5 and Mixtral to GPT-4-level. Our results show that the combination of various medical corpora and retrievers achieves the best performance. In addition, we discovered a log-linear scaling property and the "lost-in-the-middle" effects in medical RAG. We believe our comprehensive evaluations can serve as practical guidelines for implementing RAG systems for medicine.
PDF Abstract



 PubMedQA
PubMedQA
 MedQA
MedQA
 MedMCQA
MedMCQA
