MobileVLM V2: Faster and Stronger Baseline for Vision Language Model
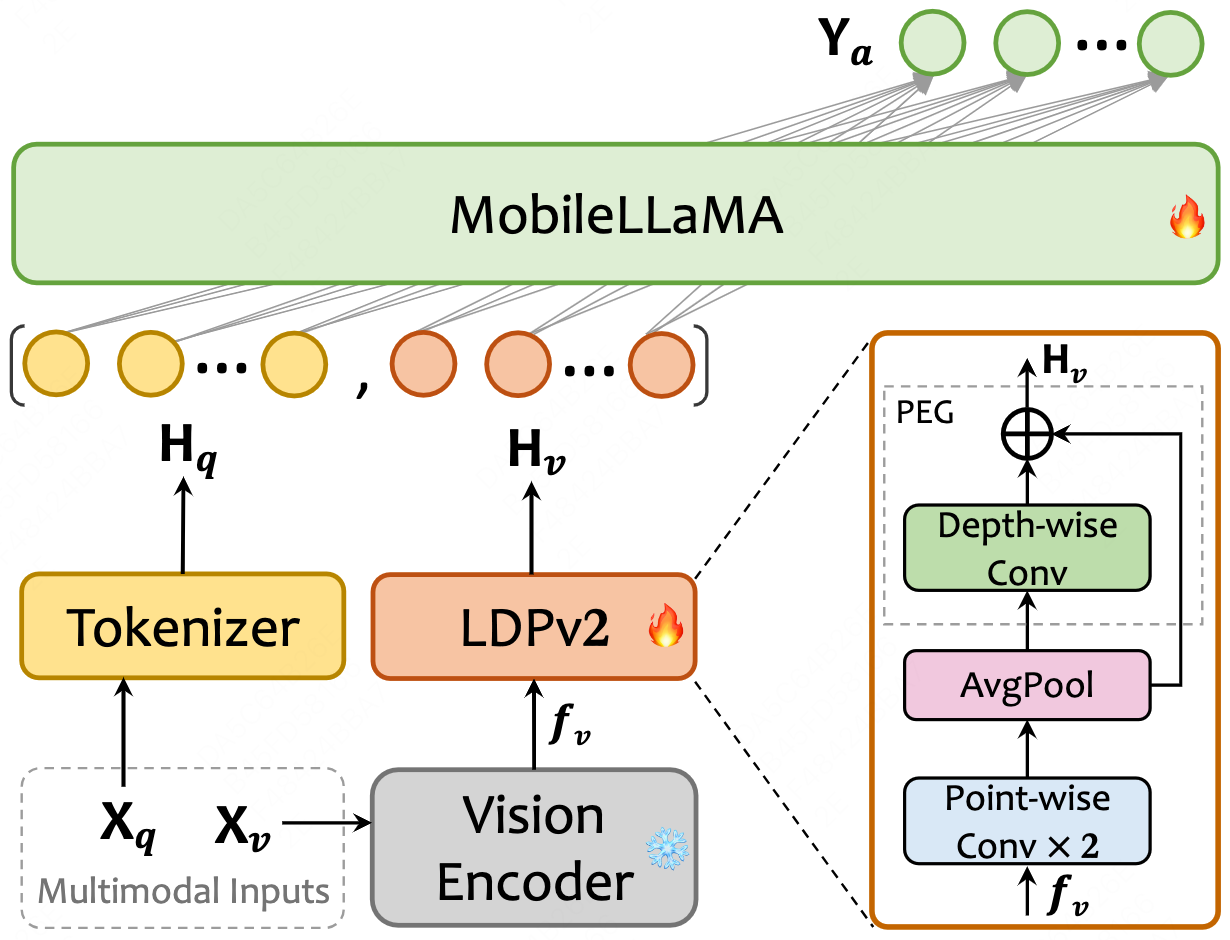
We introduce MobileVLM V2, a family of significantly improved vision language models upon MobileVLM, which proves that a delicate orchestration of novel architectural design, an improved training scheme tailored for mobile VLMs, and rich high-quality dataset curation can substantially benefit VLMs' performance. Specifically, MobileVLM V2 1.7B achieves better or on-par performance on standard VLM benchmarks compared with much larger VLMs at the 3B scale. Notably, our 3B model outperforms a large variety of VLMs at the 7B+ scale. Our models will be released at https://github.com/Meituan-AutoML/MobileVLM .
PDF AbstractCode

Tasks


 MS COCO
MS COCO
 GQA
GQA
 TextVQA
TextVQA
 ScienceQA
ScienceQA
 MMBench
MMBench
 VSR
VSR
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
