| Training Techniques | SGD with Momentum, Weight Decay, AutoAugment, Cutout, Label Smoothing |
|---|---|
| Architecture | 1x1 Convolution, Anti-Alias Downsampling, Convolution, Global Average Pooling, InPlace-ABN, Leaky ReLU, ReLU, Residual Connection, Squeeze-and-Excitation Block |
| ID | tresnet_l |
| SHOW MORE |
| Training Techniques | SGD with Momentum, Weight Decay, AutoAugment, Cutout, Label Smoothing |
|---|---|
| Architecture | 1x1 Convolution, Anti-Alias Downsampling, Convolution, Global Average Pooling, InPlace-ABN, Leaky ReLU, ReLU, Residual Connection, Squeeze-and-Excitation Block |
| ID | tresnet_l_448 |
| SHOW MORE |
| Training Techniques | SGD with Momentum, Weight Decay, AutoAugment, Cutout, Label Smoothing |
|---|---|
| Architecture | 1x1 Convolution, Anti-Alias Downsampling, Convolution, Global Average Pooling, InPlace-ABN, Leaky ReLU, ReLU, Residual Connection, Squeeze-and-Excitation Block |
| ID | tresnet_m |
| SHOW MORE |
| Training Techniques | SGD with Momentum, Weight Decay, AutoAugment, Cutout, Label Smoothing |
|---|---|
| Architecture | 1x1 Convolution, Anti-Alias Downsampling, Convolution, Global Average Pooling, InPlace-ABN, Leaky ReLU, ReLU, Residual Connection, Squeeze-and-Excitation Block |
| ID | tresnet_m_448 |
| SHOW MORE |
| Training Techniques | SGD with Momentum, Weight Decay, AutoAugment, Cutout, Label Smoothing |
|---|---|
| Architecture | 1x1 Convolution, Anti-Alias Downsampling, Convolution, Global Average Pooling, InPlace-ABN, Leaky ReLU, ReLU, Residual Connection, Squeeze-and-Excitation Block |
| ID | tresnet_xl |
| SHOW MORE |
| Training Techniques | SGD with Momentum, Weight Decay, AutoAugment, Cutout, Label Smoothing |
|---|---|
| Architecture | 1x1 Convolution, Anti-Alias Downsampling, Convolution, Global Average Pooling, InPlace-ABN, Leaky ReLU, ReLU, Residual Connection, Squeeze-and-Excitation Block |
| ID | tresnet_xl_448 |
| SHOW MORE |
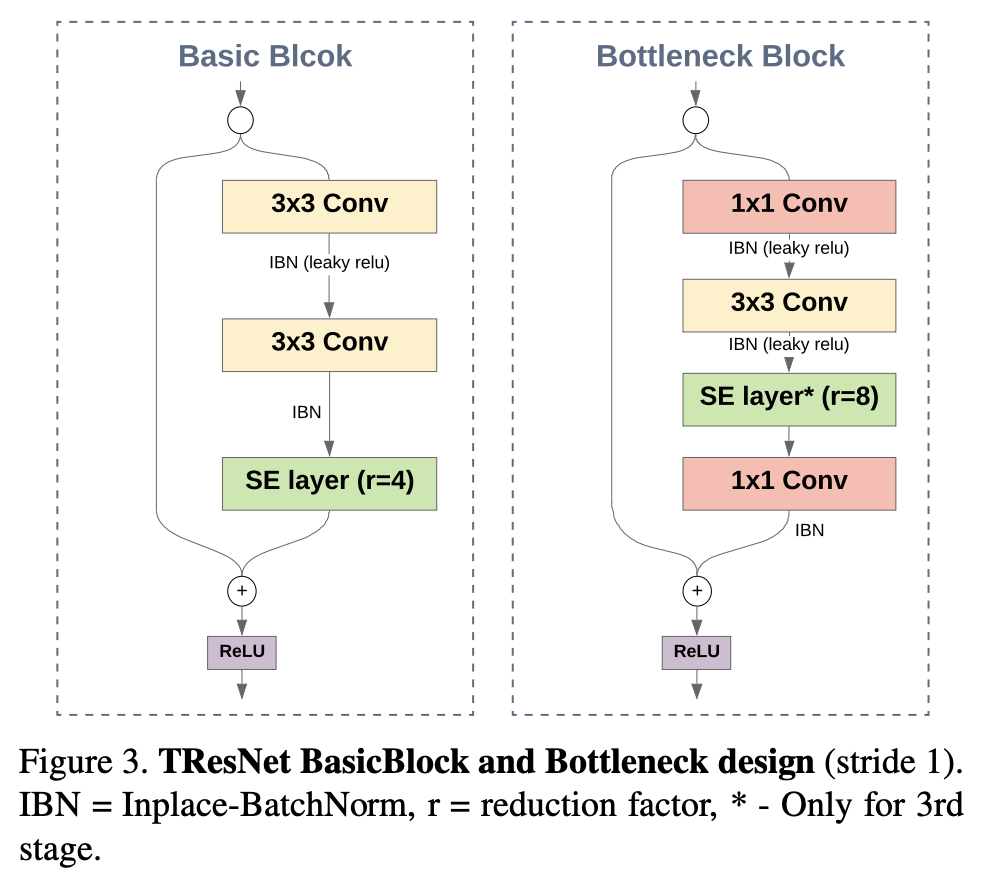
A TResNet is a variant on a ResNet that aim to boost accuracy while maintaining GPU training and inference efficiency. They contain several design tricks including a SpaceToDepth stem, Anti-Alias downsampling, In-Place Activated BatchNorm, Blocks selection and squeeze-and-excitation layers.
To load a pretrained model:
import timm
m = timm.create_model('tresnet_m', pretrained=True)
m.eval()
Replace the model name with the variant you want to use, e.g. tresnet_m. You can find the IDs in the model summaries at the top of this page.
You can follow the timm recipe scripts for training a new model afresh.
@misc{ridnik2020tresnet,
title={TResNet: High Performance GPU-Dedicated Architecture},
author={Tal Ridnik and Hussam Lawen and Asaf Noy and Emanuel Ben Baruch and Gilad Sharir and Itamar Friedman},
year={2020},
eprint={2003.13630},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
 Image Classification on ImageNet
Image Classification on ImageNet
| MODEL | TOP 1 ACCURACY | TOP 5 ACCURACY |
|---|---|---|
| tresnet_xl_448 | 83.06% | 96.19% |
| tresnet_l_448 | 82.26% | 95.98% |
| tresnet_xl | 82.05% | 95.93% |
| tresnet_m_448 | 81.72% | 95.57% |
| tresnet_l | 81.49% | 95.62% |
| tresnet_m | 80.8% | 94.86% |

