ZeroGen: Zero-shot Multimodal Controllable Text Generation with Multiple Oracles
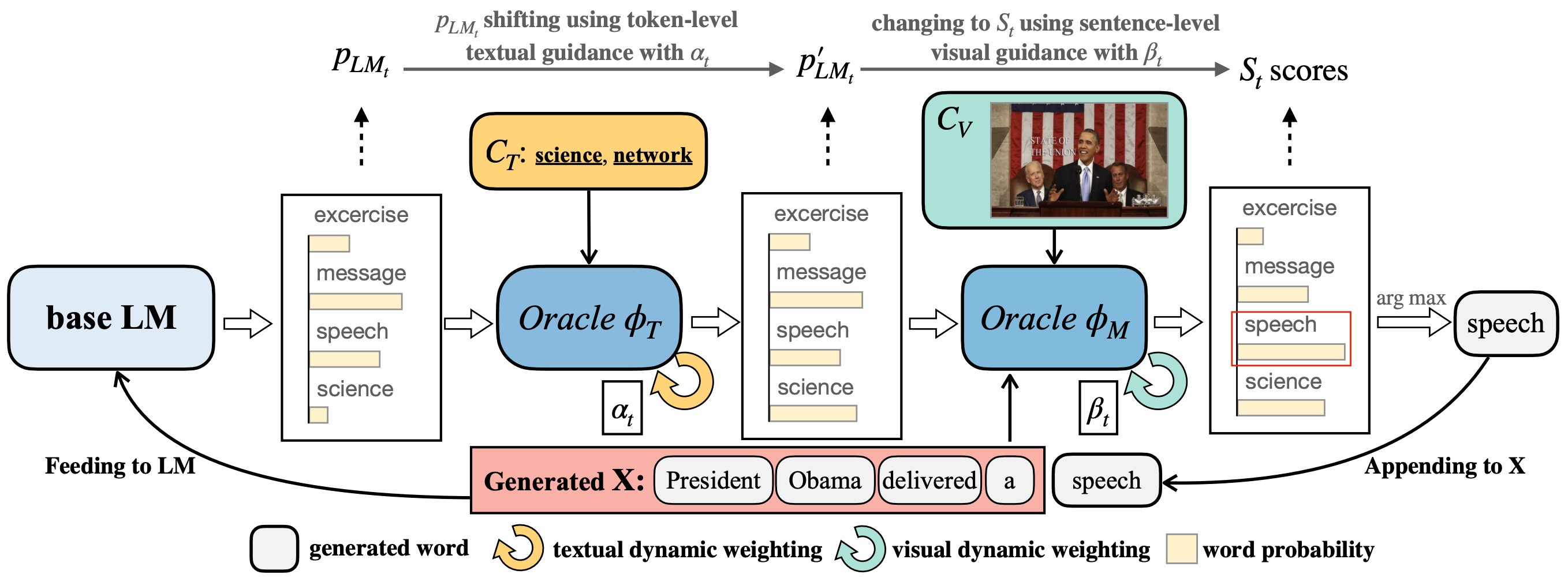
Automatically generating textual content with desired attributes is an ambitious task that people have pursued long. Existing works have made a series of progress in incorporating unimodal controls into language models (LMs), whereas how to generate controllable sentences with multimodal signals and high efficiency remains an open question. To tackle the puzzle, we propose a new paradigm of zero-shot controllable text generation with multimodal signals (\textsc{ZeroGen}). Specifically, \textsc{ZeroGen} leverages controls of text and image successively from token-level to sentence-level and maps them into a unified probability space at decoding, which customizes the LM outputs by weighted addition without extra training. To achieve better inter-modal trade-offs, we further introduce an effective dynamic weighting mechanism to regulate all control weights. Moreover, we conduct substantial experiments to probe the relationship of being in-depth or in-width between signals from distinct modalities. Encouraging empirical results on three downstream tasks show that \textsc{ZeroGen} not only outperforms its counterparts on captioning tasks by a large margin but also shows great potential in multimodal news generation with a higher degree of control. Our code will be released at https://github.com/ImKeTT/ZeroGen.
PDF Abstract


 Flickr30k
Flickr30k
 COCO Captions
COCO Captions
 FlickrStyle10K
FlickrStyle10K
