Zero-Shot and Few-Shot Video Question Answering with Multi-Modal Prompts
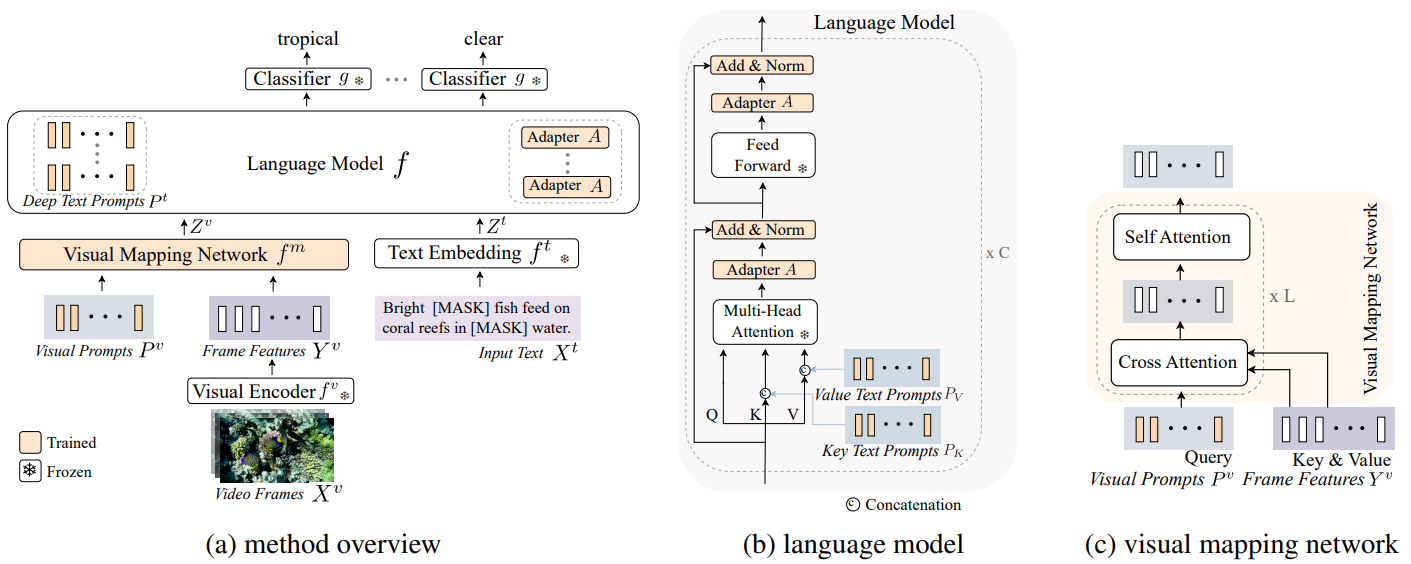
Recent vision-language models are driven by large-scale pretrained models. However, adapting pretrained models on limited data presents challenges such as overfitting, catastrophic forgetting, and the cross-modal gap between vision and language. We introduce a parameter-efficient method to address these challenges, combining multimodal prompt learning and a transformer-based mapping network, while keeping the pretrained models frozen. Our experiments on several video question answering benchmarks demonstrate the superiority of our approach in terms of performance and parameter efficiency on both zero-shot and few-shot settings. Our code is available at https://engindeniz.github.io/vitis.
PDF AbstractCode



Datasets
 MSR-VTT
MSR-VTT
 MSVD
MSVD
 WebVid
WebVid
 ActivityNet-QA
ActivityNet-QA
 TGIF-QA
TGIF-QA
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
