When Parameter-efficient Tuning Meets General-purpose Vision-language Models
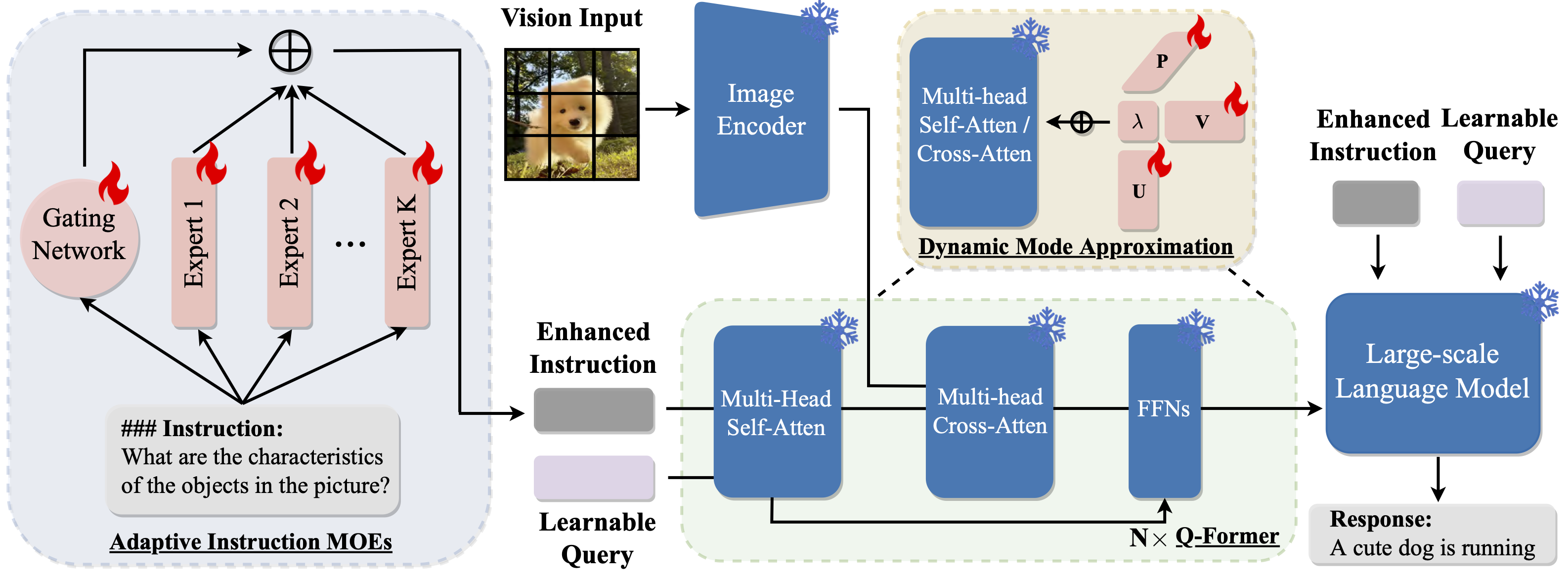
Instruction tuning has shown promising potential for developing general-purpose AI capabilities by using large-scale pre-trained models and boosts growing research to integrate multimodal information for creative applications. However, existing works still face two main limitations: the high training costs and heavy computing resource dependence of full model fine-tuning, and the lack of semantic information in instructions, which hinders multimodal alignment. Addressing these challenges, this paper proposes a novel approach to utilize Parameter-Efficient Tuning for generAl-purpose vision-Language models, namely PETAL. PETAL revolutionizes the training process by requiring only 0.5% of the total parameters, achieved through a unique mode approximation technique, which significantly reduces the training costs and reliance on heavy computing resources. Furthermore, PETAL enhances the semantic depth of instructions in two innovative ways: 1) by introducing adaptive instruction mixture-of-experts(MOEs), and 2) by fortifying the score-based linkage between parameter-efficient tuning and mutual information. Our extensive experiments across five multimodal downstream benchmarks reveal that PETAL not only outperforms current state-of-the-art methods in most scenarios but also surpasses full fine-tuning models in effectiveness. Additionally, our approach demonstrates remarkable advantages in few-shot settings, backed by comprehensive visualization analyses. Our source code is available at: https://github. com/melonking32/PETAL.
PDF Abstract
 Flickr30k
Flickr30k
 OK-VQA
OK-VQA
 TextVQA
TextVQA
 A-OKVQA
A-OKVQA
