What Do Self-Supervised Speech Models Know About Words?
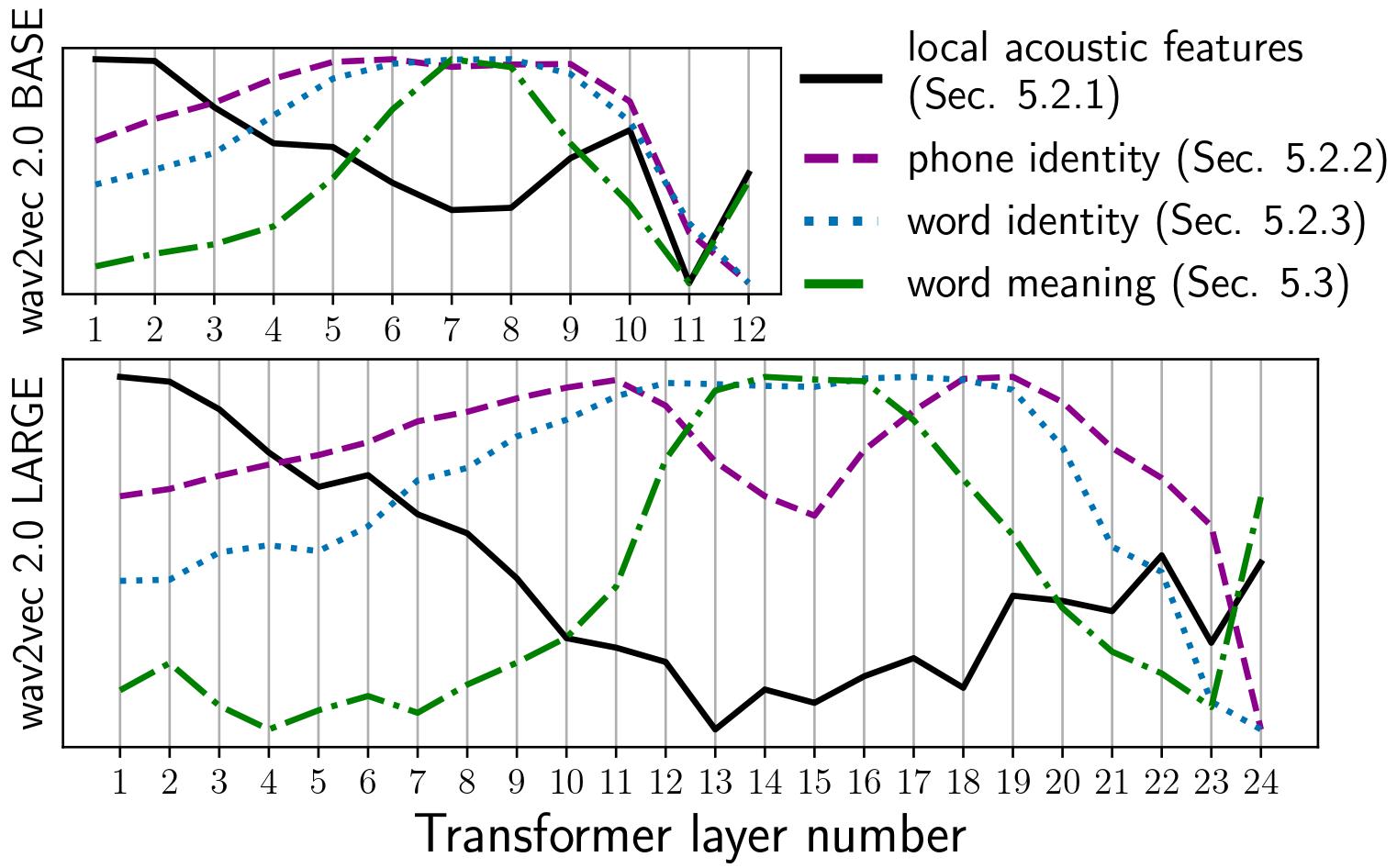
Many self-supervised speech models (S3Ms) have been introduced over the last few years, improving performance and data efficiency on various speech tasks. However, these empirical successes alone do not give a complete picture of what is learned during pre-training. Recent work has begun analyzing how S3Ms encode certain properties, such as phonetic and speaker information, but we still lack a proper understanding of knowledge encoded at the word level and beyond. In this work, we use lightweight analysis methods to study segment-level linguistic properties -- word identity, boundaries, pronunciation, syntactic features, and semantic features -- encoded in S3Ms. We present a comparative study of layer-wise representations from ten S3Ms and find that (i) the frame-level representations within each word segment are not all equally informative, and (ii) the pre-training objective and model size heavily influence the accessibility and distribution of linguistic information across layers. We also find that on several tasks -- word discrimination, word segmentation, and semantic sentence similarity -- S3Ms trained with visual grounding outperform their speech-only counterparts. Finally, our task-based analyses demonstrate improved performance on word segmentation and acoustic word discrimination while using simpler methods than prior work.
PDF Abstract


 LibriSpeech
LibriSpeech
