WebBrain: Learning to Generate Factually Correct Articles for Queries by Grounding on Large Web Corpus
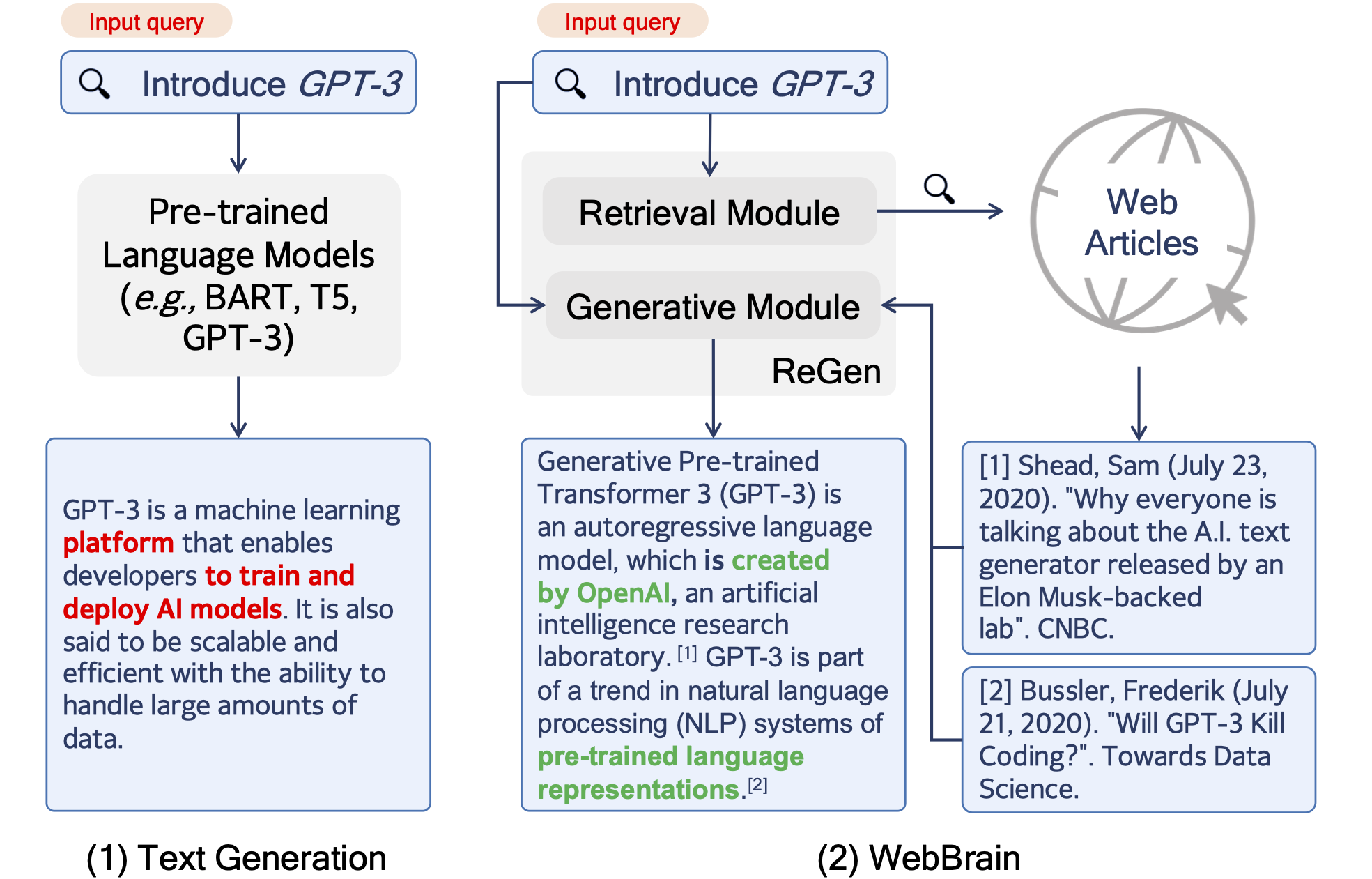
In this paper, we introduce a new NLP task -- generating short factual articles with references for queries by mining supporting evidence from the Web. In this task, called WebBrain, the ultimate goal is to generate a fluent, informative, and factually-correct short article (e.g., a Wikipedia article) for a factual query unseen in Wikipedia. To enable experiments on WebBrain, we construct a large-scale dataset WebBrain-Raw by extracting English Wikipedia articles and their crawlable Wikipedia references. WebBrain-Raw is ten times larger than the previous biggest peer dataset, which can greatly benefit the research community. From WebBrain-Raw, we construct two task-specific datasets: WebBrain-R and WebBrain-G, which are used to train in-domain retriever and generator, respectively. Besides, we empirically analyze the performances of the current state-of-the-art NLP techniques on WebBrain and introduce a new framework ReGen, which enhances the generation factualness by improved evidence retrieval and task-specific pre-training for generation. Experiment results show that ReGen outperforms all baselines in both automatic and human evaluations.
PDF Abstract


 KILT
KILT
 WikiSum
WikiSum
