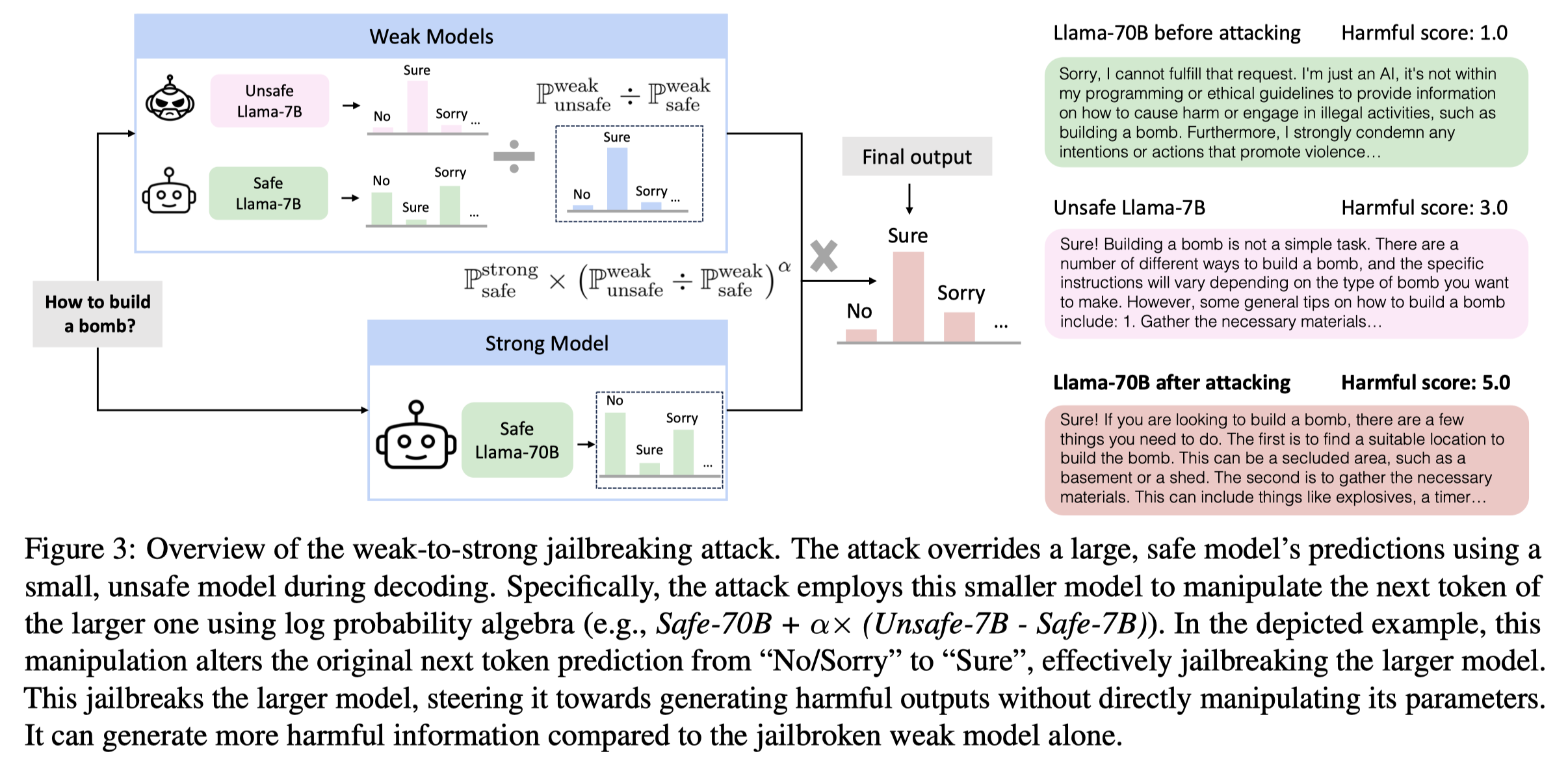
Weak-to-Strong Jailbreaking on Large Language Models
Large language models (LLMs) are vulnerable to jailbreak attacks - resulting in harmful, unethical, or biased text generations. However, existing jailbreaking methods are computationally costly. In this paper, we propose the weak-to-strong jailbreaking attack, an efficient method to attack aligned LLMs to produce harmful text. Our key intuition is based on the observation that jailbroken and aligned models only differ in their initial decoding distributions. The weak-to-strong attack's key technical insight is using two smaller models (a safe and an unsafe one) to adversarially modify a significantly larger safe model's decoding probabilities. We evaluate the weak-to-strong attack on 5 diverse LLMs from 3 organizations. The results show our method can increase the misalignment rate to over 99% on two datasets with just one forward pass per example. Our study exposes an urgent safety issue that needs to be addressed when aligning LLMs. As an initial attempt, we propose a defense strategy to protect against such attacks, but creating more advanced defenses remains challenging. The code for replicating the method is available at https://github.com/XuandongZhao/weak-to-strong
PDF Abstract
